介绍
概述
-
应用:
- 数据生成
- 图片翻译
- 风格迁移
- 超分辨率
- 图像修复
- 等等等等
-
发展:
科�研领域关注度指数型增长
过去十年机器学习领域最有趣的想法之一
- 网络结构
- 条件生成网络
- 图像翻译
- 归一化和限制
- 损失函数
- 评价指标
-
什么是 GAN:
- 不同于分类、分割、目标检测等判别模型,GAN 是一种生成模型,通过随机噪声来生成对应数据。
原理
基础结构:
-
GAN 包括生成器和判别器,基础结构如下:
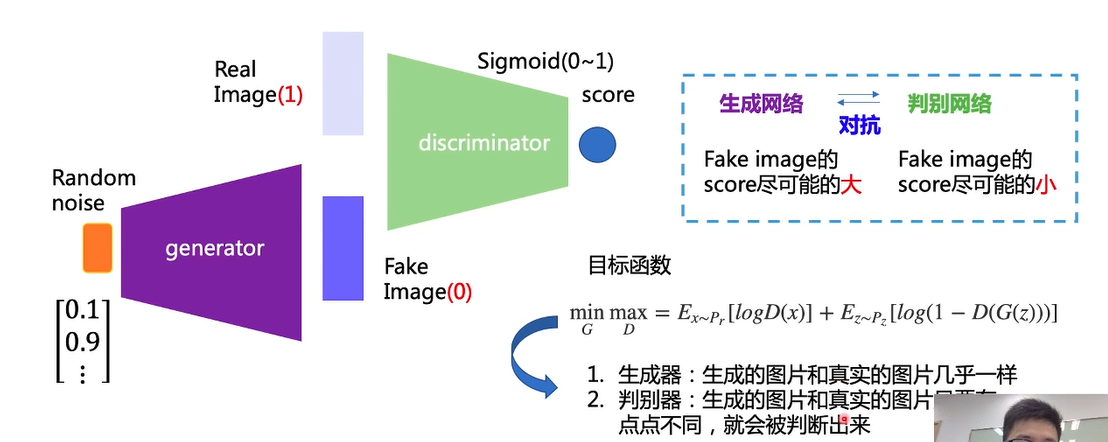
-
Auto Encoder:
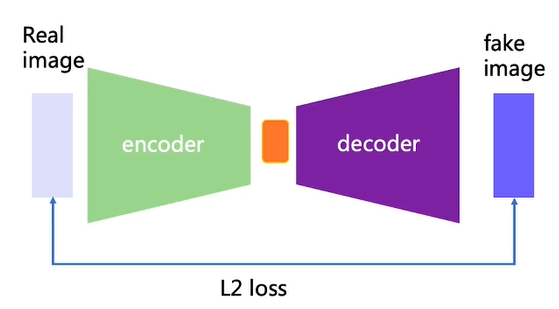
我们对整个网络进行训练,但是最终只保留 decoder 部分,那么它与 GAN 有什么区别呢
-
Auto Encoder 使用 L2 loss,在 point-wise 上进行优化,虽然效果稳定但是模糊;GAN 使用 Distribution match(分布匹配) 的方法,效果清晰但是不够稳定。
因此很多任务如图像翻译、超分辨率重建等都将这二者结合使用。
一点点理论:
-
生成器将输入的随机噪�声由原来的分布映射到最终所需要的分布,并由判别器与其对抗来不断优化。
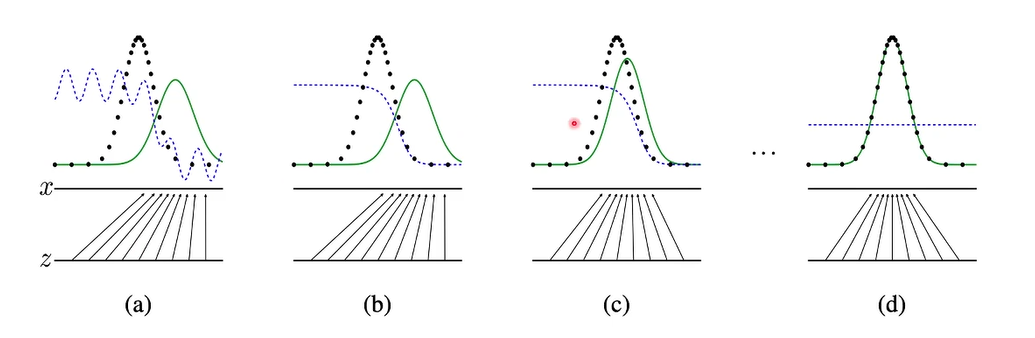
-
判别器训练:
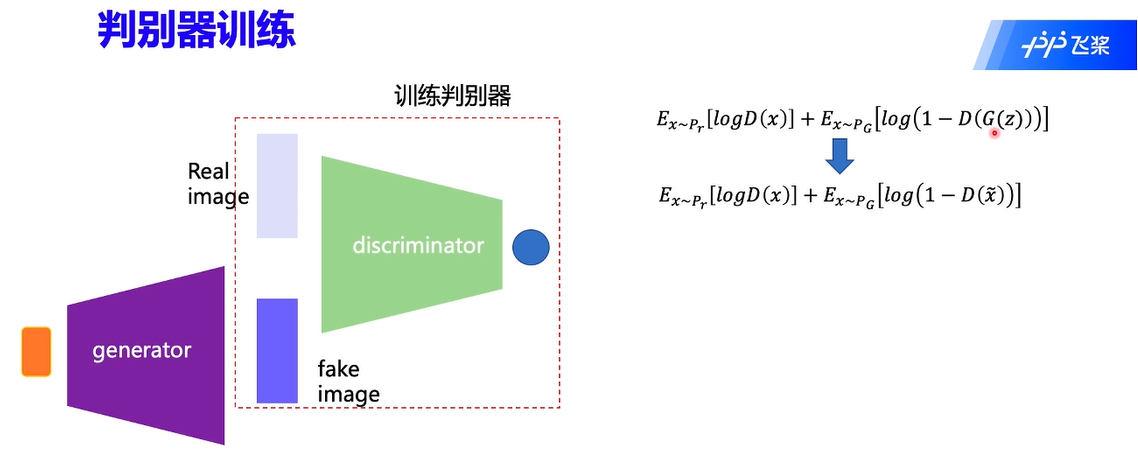
判别器训练时会冻结生成器的参数,且将生成的 fake image 标签置为 0,其损失函数为二分类的交叉熵函数。
-
生成器训练:
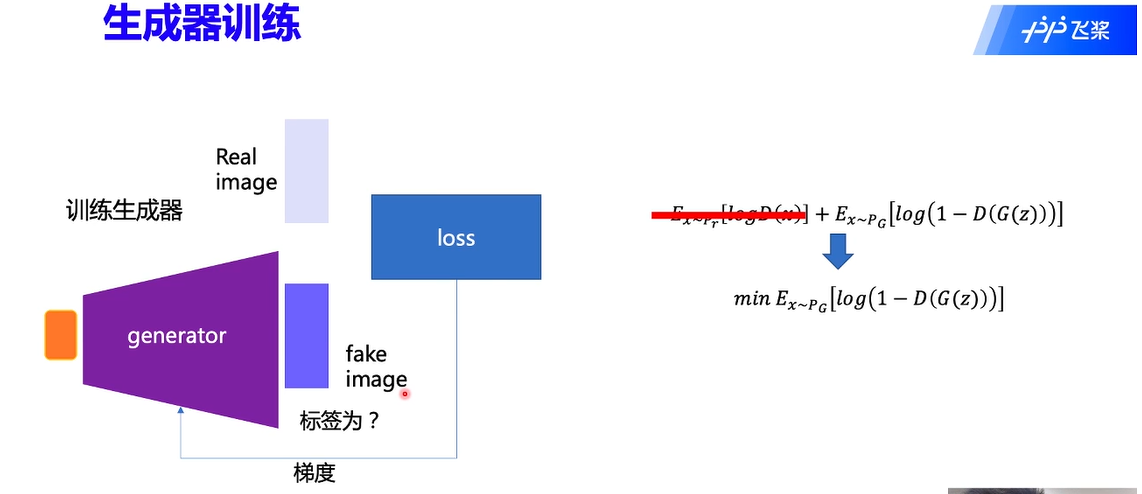
生成器训练时同样会固定判别器的参数,此时判别器相当于一个损失函数。我们去掉不相关的部分可得到如下:
在这里,我们将 fake image 的标签置为 1。
将 label 设置为 1 交给判别器判别,通过 loss 即可以知道生成器的生成情况如何,这是一种“欺骗”行为。
-
GAN 的目标:
生成器:生成的图片和真实图片几乎一样
判别器:生成的图片和真实图片只要有一点不同,就会被判断出来
最终我们只需要生成器
损失函数
总损失函数:
\begin{eqnarray} \underset{G}{min} \underset{D}{max}L(D,G)&=&E_{x\sim P_r}[\log D(x)]+E_{z\sim P_g}[\log (1-D(G(z)))]\\ &=&E_{x\sim P_r}[\log D(x)]+E_{x\sim P_g}[\log (1-D(\widetilde{x}))] \end{eqnarray}判别器损失函数:
生成器损失函数:
其中 指的是
GAN 技术的演进
DCGAN
-
结构:
最初的 GAN:
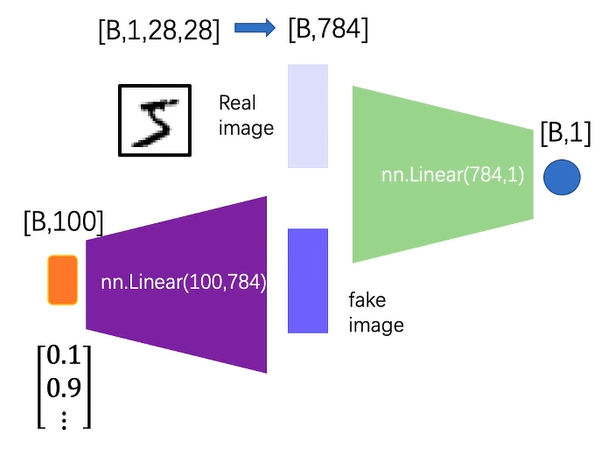
DCGAN(Deep Convlutional GAN):
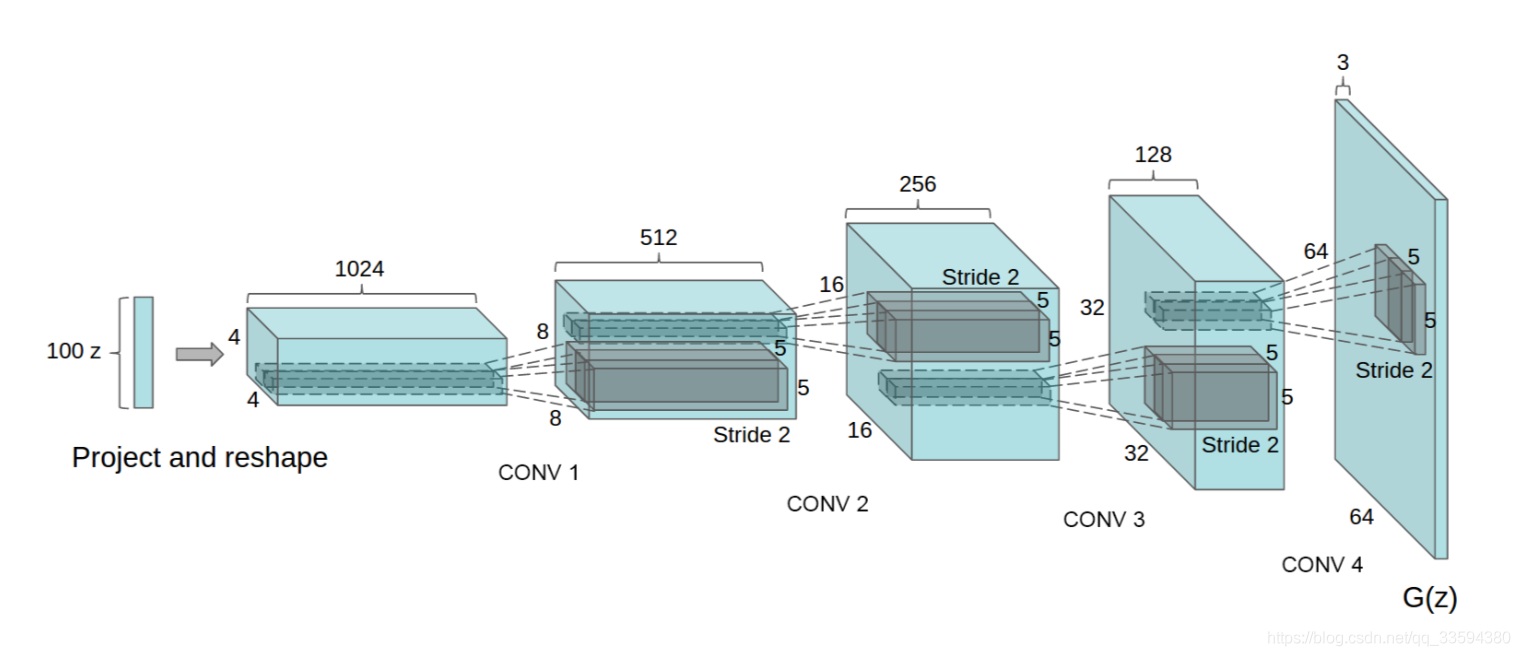
DCGAN 主要做了一下改进:
- 使用卷积层代替全连接层
- 添加了 BatchNorm
- 在生成器中使用 ReLU
- 在判别器中使用 LeakyReLU
-
生成手写数字训练过程代码:
import torch
import torch.nn as nn
import torch.optim as optim
# Initialize BCELoss function
criterion = nn.BCELoss()
real_label = 1
fake_label = 0
# Setup Adam optimizers for both G and D
optimizerD = optim.Adam(netD.parameters(), lr=0.002, betas=(
0.9, 0.999), eps=1e-08, weight_decay=0)
optimizerG = optim.Adam(netG.parameters(), lr=0.002, betas=(
0.9, 0.999), eps=1e-08, weight_decay=0)
losses = [[], []]
now = 0
for epoch in range(len(epoch_num)):
netD.train()
netG.train()
for i, (data, target) in enumerate(dataloader):
""" 首先训练判别器
先使用真图进行训练
在使用生成器生成的假图进行训练
"""
optimizerD.zero_grad()
real_img = data # 使用真实图像
labels = torch.ones((batch_size, 1, 1, 1)) # label全部设置为1
real_out = netD(real_img)
lossD_real = criterion(real_out, labels)
lossD_real.backward()
noise = torch.randn((batch_size, 100, 1, 1)) # 生成噪声
fake_img = netG(noise) # 生成伪图
labels = torch.zeros((batch_size, 1, 1, 1)) # label设置为0
fake_out = netD(fake_img.detach())
lossD_fake = criterion(fake_out, labels)
lossD_fake.backward()
optimizerD.step()
optimizerD.zero_grad()
lossD = lossD_fake+lossD_real
losses[0].append(lossD.numpy())
""" 训练生成器
注意将label设置为1
"""
optimizerG.zero_grad()
noise = torch.randn((batch_size, 100, 1, 1)) # 生成噪声
fake = netG(noise) # 生成伪图
labels = torch.ones((batch_size, 1, 1, 1))# 将label设置为1
output = netD(fake) # 判别器进行判断
lossG = criterion(output, labels)
lossG.backward()
optimizerG.step()
optimizerG.zero_grad()
losses[1].append(lossG.numpy())
LSGAN
原始的 GAN 和 DCGAN 存在两个问题:模式坍塌,训练不稳定
模式坍塌,即多样性不足:
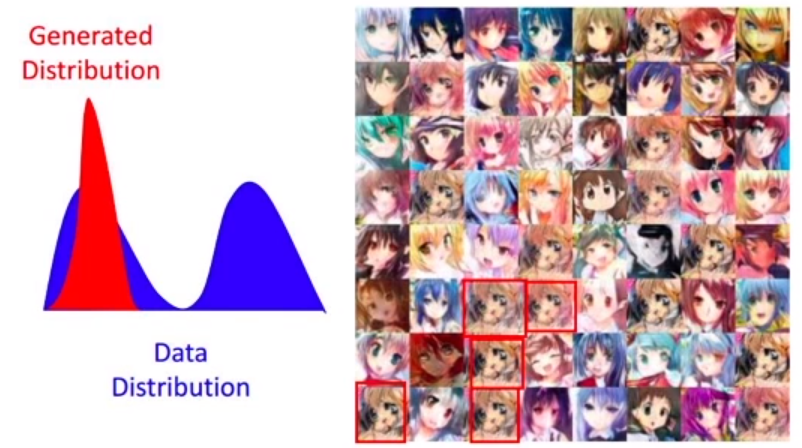
其原因是网络只学习到了真实分布的一部分。
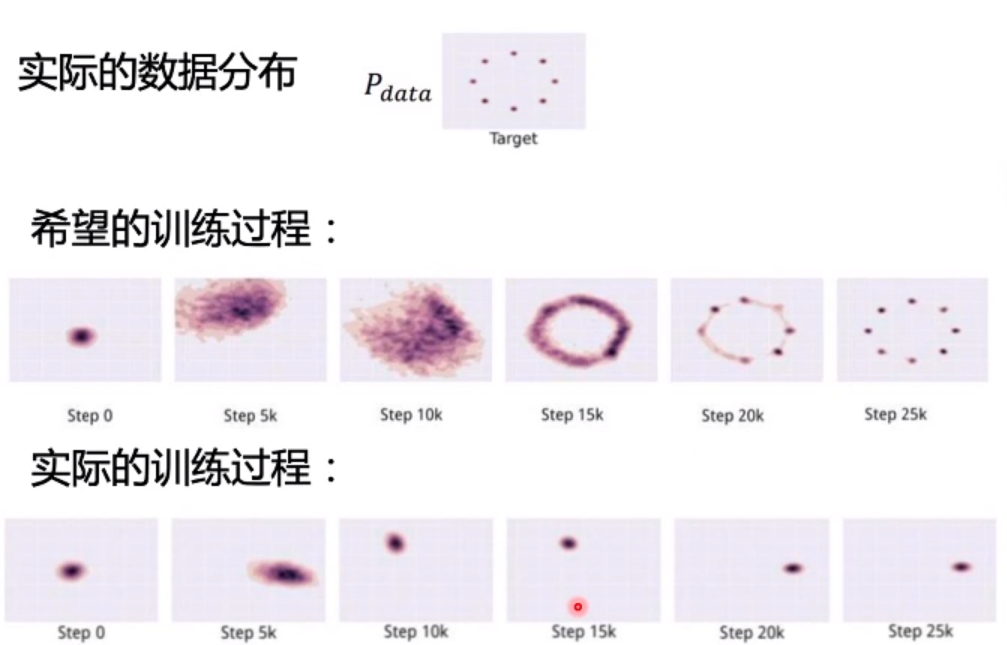
训练不稳定
函数函数函数首先让我们来推导 GAN 的损失函数存在的问题:
判别器的损失函数