Cyclegan for music generate
论文名称:Symbolic Music Genre Transfer with CycleGAN
作者:Gino Brunner, Yuyi Wang, Roger Wattenhofer and Sumu Zhao
Code:https://github.com/sumuzhao/CycleGAN-Music-Style-Transfer
��前言
本文使用 Cycle Gan 实现了不同音乐类型的转换,在原有模型的基础上,引入了新的 loss 提升生成的音乐质量。
网络结构
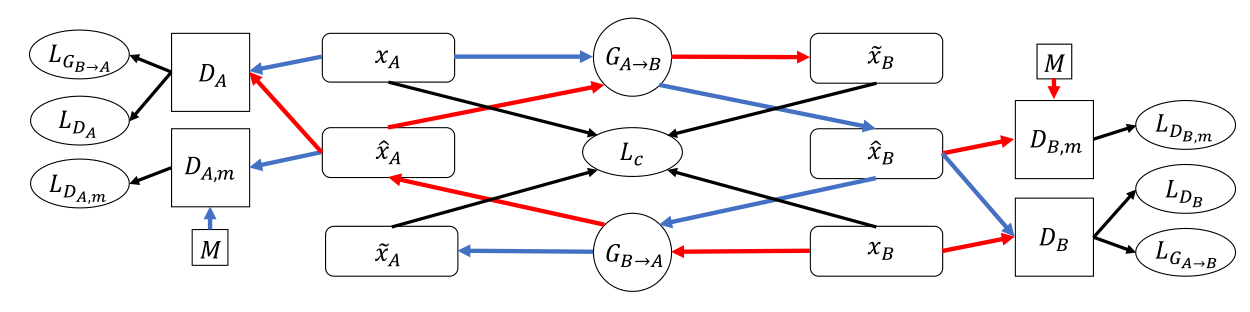
标识(嫌太麻烦可以先看 2.1):
- 蓝线:表示从
源域A到目标域B再到源域A的转换 - 红线:表示从
目标域B到源域A再到目标域B的转换 - 黑线:指向损失函数
- :表示在两个域之间转换的生成器
- :表示两个域的判别器
- 表示两个额外的判别器,其迫使生成器学习更多的高级特征
- :表示来自
源域A和目标域B中的真实样本数据,同时也是网络的输入 - :表示转换到
目标域B的样本数据,记为 - :表示转换回
目标域B的样本数据,记为 - :表示转换回
源域A的样本数据,记为 - :表示转换到
源域A的样本数据,记为 M:是一个包含多个域的音乐集,例如 ,但也可能- :表示来自 M 的样本数据
对于各种样本数据,带有 上标表示 中间输出,带有 上标表示 最终输出
简化结构
让我们分以下几步来简化这个结构
- 忽略判别器,把它当作一个损失函数
- 只提取出其中的
接下来,让我们仅仅针对 来看一下它的对抗网络之旅
- 首先 会输入 得到
中间输出 - 会输入 得到
最终输出
至此,我们称这是一个循环,我们会对 中间输出 和 求损失
同理,对于 ,会进行一个 反向 的循环,即先输给 再输入给 ,得到 和 ,同样会对 和 求损失
此时我们得到了两个最终输出 ,分别和 求损失 ( 见下循环一致损失)
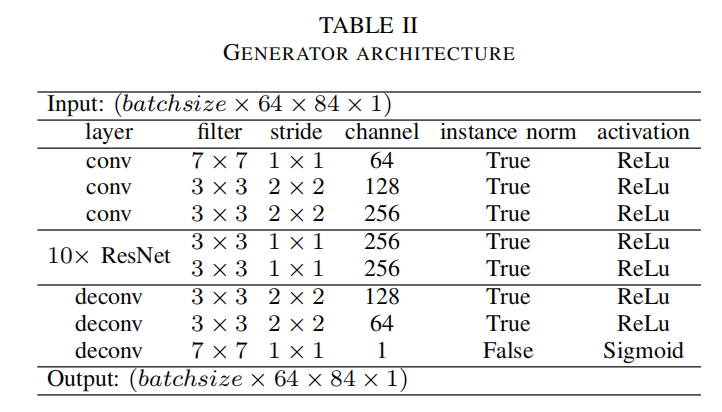
生成器结构
生成器结构如下,不是很复杂

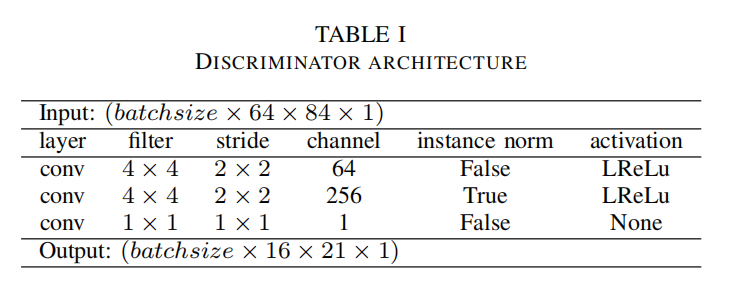
判别器结构
判别器的结构十分简单,激活函数替换为 Leaky ReLU
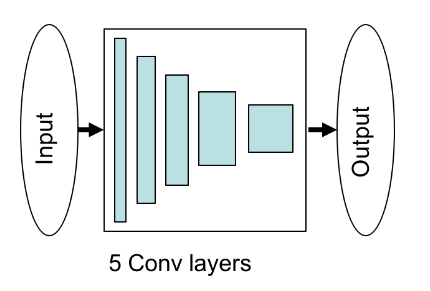
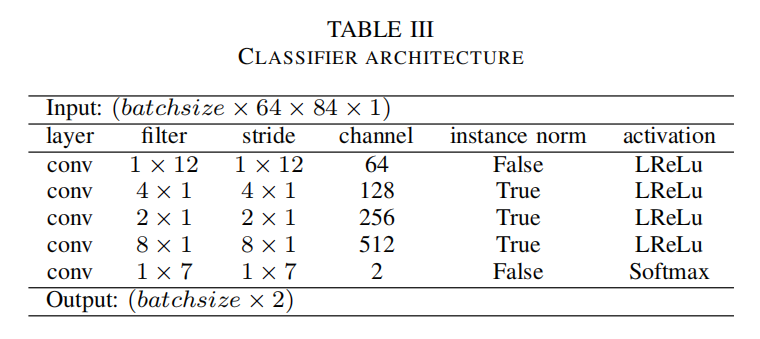
分类器结构
分类器是作者单独提出用来分类分格迁移的音乐有没有达到效果
损失函数
生成器损失
总损失如下
其分为两个部分:对抗损失和循环一致损失
这里的 表示循环一致损失的权重,论文中是 10
对抗损失
使用 来作为生成器的损失
对于生成器,我们希望其生成的数据都被判定为真,从而欺骗判别器,因此这里 减去1,1 即代表着标签
循环一致损失
在此前的工作中,为了加强前后一致性,进入了一个 作为损失项,被称为循环一致损失 ( cycle consistency loss)
循环一致损失保证了输入经过两个生成器之后,即完成了一次循环,最终能被映射回自身
如果取消循环一致损失,输入与输出之间的关系将大大减弱
同时,循环一致损失也可以看做一个正则化项,它保证了生成器不忽略输入的数据,而是保留更多必要信息,以完成反向转换
判别器损失
GAN 的训练是高度不平衡的,通常在早期判别器会过度强大,从而导致网络收敛到一个很差的局部最优
此外,对于风格迁移任务还存在着另一个困难:生成器需要学习源域和目标域的两种特征来欺骗判别器,然而生成器可以通过生成某种音乐类型独有的模式来欺骗判别器(我在复现的过程中也确实遇到了这种情况),这样即使判别器被欺骗了,生成器的生成也不一定是真实的。因此添加了两个额外的判别器通过学习混合域的音乐来迫使生成器学习到更优的高级特征,并且使用了约束损失(我自己这么叫的)
其中 用来加权鉴别器的额外损失,论文中是 1
为了保持训练的稳定性,同时添加了�高斯噪声到判别器的输入(这应该是为了缓解判别器前期过于强大的情况)
标准判别器损失
约束损失
主要使用生成的假数据和多个域中的数据 进行训练
这有助于使生成器保持在“音乐流形”上,并生成逼真的音乐。更重要的是,它让生成器保留了许多输入结构,从而确保在转换后仍然能够识别出原始内容。
简单来说,我认为这两个判别器起到了一个 约束 的作用,其目的是将生成的音乐约束限制在音乐域 中,从而解决上述第二个问题
先将生成器生成约束在 真实音乐 的范围,再由其他判别器和损失函数增强其相应音乐风格转换的能力
数据集和处理
MIDI 格式
与波形文件不同,MIDI 文件不对音乐进行采样,而是将每一个音符记录为一个数字
虽然 midi 缺乏重现真实自然声音的能力,但是这是一种很好的将音乐离散化的方法
MIDI 文件拥有 note on 和 note off 两种信号,note on 消息指示一个音符开始被演奏,它还指定了该音符的速度 (响度)。note off 消息表示一个注释的结束。
采样策略
我们以每小节 16 个时间步对 MIDI 文件进行采样,因为绝大部分部分小节当中一个拍子的音符时值都不会低于十六分音符
我们最终的数据维度是 , 分别表示采样时间步的大小和音高
同时将速度都设置为 127,使他们的响度保持一致,这会使学习更简单,因为只有 note on 和 note off 两种状态
于是,数据维度也是表示为在每个时间步上包含一个 维的 向量, 为同时弹奏的音,此外,MIDI 的音域大于钢琴的音域,我们只取了 ,使用连续的 4 个小节作为而训练数据,因此数据维度大小为
音轨
一首乐曲通常有很多音轨,若是忽略了伴奏会丢失很多原有的信息,因此,做了一个简单的处理:将所有音轨合并为一个音轨。
这样可以保留大部分原有信息,然而所有的不同音轨通常由不同乐器演奏,这样一来,所有音轨都会变为一种乐器演奏,生成时便会显得十分凌乱
此外,还去除了鼓的音轨,因为使用其他乐器演奏他通常很奇怪
数据处理
首先,过滤掉第一拍不以 0 开始的 MIDI 文件
然后删除掉拍号不为 4/4 拍或者会在中途改变的曲目
最终得到 12,341 个爵士、16,545 个古典和 20,780 个流行音乐采样,每个文件包含 4 个小节
为了避免不同流派音乐数据的不均衡,训练时会减少大数据集的样本数,与小数据集进行匹配,如当训练爵士和古典时,从古典音乐中随即抽取 12,341 个文件
在预处理阶段,将数据归一化
代码复现
原论文是 TensorFlow 实现的,我这里使用 pytorch 进行了复现,想吐槽的一点就是作者论文的参数和代码�写的不一样,原论文引入了 Instance Norm 和 LeakyReLU,使用 Adam 优化器,,,,,。
但是复现的效果不是很好,当训练次数过多时,就遇到了文中提到的问题——生成器通过生成某种音乐类型独有的模式来欺骗判别器,虽然 loss 已经降到了足够低,但是几乎所有风格迁移的音乐几乎都一摸一样,我训练的是古典 - 爵士,几乎所有迁移的音乐都是一阵沉默然后突然巨响一下,可能这就是判别器学习到的古典音乐吧。
后来降低了训练 epoch 的数量,效果就好了很多,后续可以尝试提高循环一致损失和判别器约束损失的权重,可能会缓解上述问题。
复现地址如下:
https://github.com/Asthestarsfalll/Symbolic-Music-Genre-Transfer-with-CycleGAN-for-pytorch