2023开源之夏项目申请书
DEMO 都写了还没中选,麻了,最后也没看到有人提交这个项目。
OpenMMLab 模型打包工具项目申请书
| 项目导师 | xxx |
| 申请人 | xxx |
| 日期 | 2023-06-03 |
| 版本号 | V1.0 |
一、概述
相关背景
OpenMMLab 作为当下国内最活跃的深度学习社区之一,旨在为计算机视觉领域的研究人员和从业者提供高质量、易用性和可扩展性的模型和工具。其开发套件采用模块化设计,通过 config 构建模型,带来了模型结构配置灵活,易于维护扩展等优势。但另一方面,这种设计下模型组件的代码较为分散,继承较多,嵌套复杂,一方面给用户理解和调试代码带来了一些难度,另一方面难于将特定的代码独立于 OpenMMLab 算法库使用,如迁移模型到用户自己的项目中,因此十分有必要实现一个模型打包工具。
功能目标
给定模型 config 以及 checkpoint(可选),本打包工具需要将模型、数据集、数据预处理、训练、测试、推理等必需的代码�组织并打包成一个最小工程,使其能够独立运行简单的训练、测试和推理任务。
同时,要求尽可能简化继承关系,消除不必要的继承。
最后,完全将代码展开到 PyTorch 级别,即可以完全不依赖与 OpenMMlab 系列套件的情况下运行。
二、相关调研
Torch Dynamo
Torch Dynamo 是 PyTorch 推出的划版本号作品,其基于 PEP 523 扩展了 Eval Frame,能够动态地从用户代码中抓取计算图,并进行优化。
这类利用 Eval Frame 的方法的最大优点便是动态、灵活 ,可以在运行时获取相应的 code 对象,进而获取其所在文件,对分析文件/函数/类/变量之间的依赖关系较为友好,但是在修改代码方面较为繁琐(需要修改字节码)。
AST
AST (Abstract Syntax Tree) 即抽象语法树,它是一种树形的数据结构,用于表示编程语言中代码的语法结构。在程序编译过程中,源代码首先被解析成 AST,然后再被转化成目标代码。AST 通常由节点和边组成,每个节点代表一个语法结构元素(如关键字、运算符、变量名等),而边则表示这些元素之间的关系(如赋值语句中等号两侧的表达式之间的关系)。AST 可以用于各种静态分析操作,例如语法检查、代码重构、性能优化以及代码生成等。
Python 标准库中的 ast 模块提供了许多工具用于��操作和分析 Python AST,Python AST 中的每个节点代表一个 Python 语言中的语法结构,如函数、循环、赋值、二元操作符等。节点之间通过父子关系组成了一棵树形结构,每个节点包含有关其父节点和子节点的信息,以及该节点表示的具体语法结构所需的其他信息,例如变量名、常量值、操作符类型等。PyTorch、Paddle 中都使用过 AST 进行静态分析操作。
理论上通过 AST 分析函数/类/变量/文件之间的依赖关系,是完全可以达成项目要求的。
OpenMMLab 算法库
OpenMMLab 搭建了深度学习时代最完整的计算机视觉开源算法体系,深受广大深度学习从业者的喜爱。得益于其注册机制与配置系统,OpenMMLab 算法库可以灵活便捷地修改参数配置、实现算法模块化、提高算法复用、更加易于扩展,可正所谓成也萧何,败也萧何,此机制也大大限制了刚入门的萌新小白,提高了理解、修改代码的门槛,由此可见本项目的意义深远。
本项目的重难点也在利用和消除这套注册 - 配置系统。
三、对比分析
Dynamo 借助 Cpython Eval Frame 实现了动态分析,给我们提供了一种新的思路。Dynamo 虽然足够灵活,但是仍然存在一些缺陷,如真的会运行一遍代码,需要更改的字节码数量较多,不便于修改代码。其主要目的是在运行时实现动态地优化代码,而静态分析已完全满足本项目的需求,因此本方案选择使用 AST 抽象语法树进行实�现。
四、设计思路与可行性验证
本节包含本任务整体设计思路,实现方案与可行性验证,实际实现可能会有所变动。
在正式开始介绍设计思路之前,此处实现了一个简单的 demo 作为可行性验证:https://github.com/Asthestarsfalll/CodeSlim
目前此 demo 可以实现简单的文件/函数/类级别打包(见 tests/file_segment_level/origin/),而对于扁平化类继承仅添加了相关代码(见 codeslim/codegen.py),目前尚不能实现目标,还需要更多处理。
设计思路
主要设计思路如下图所示:
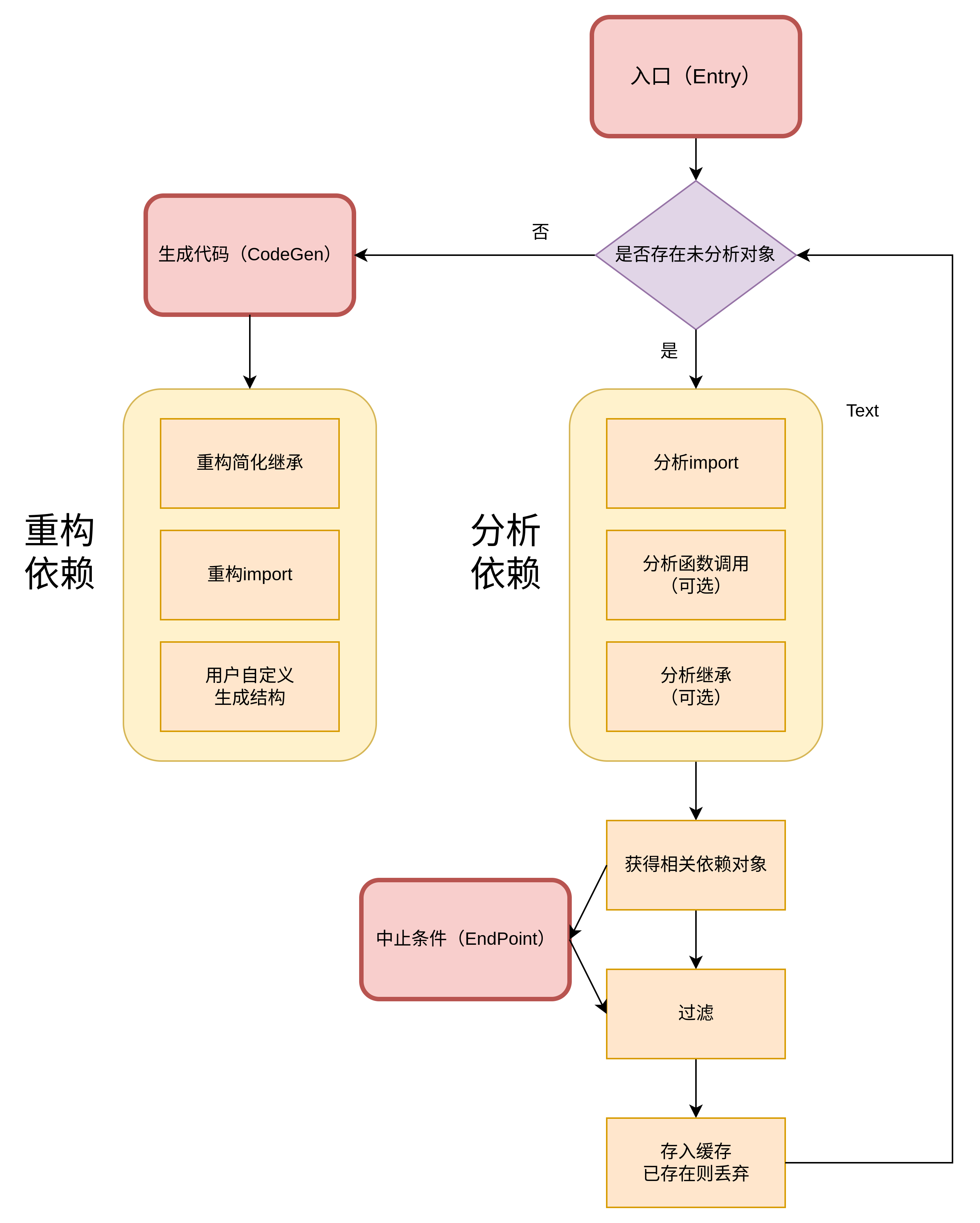
上图的 Entry 可以是 file(s),string 或 AST node,对于本任务来说,由于 MM 系列的特殊注册机制,我们需要先通过给定的 配置文件 找到对应的 model, dataset, transform, modules, runner 等的入口文件,再加上固定的 train, val 和 infer 文件。
EndPoint 则是 trace 的终止条件,如文件是否在 Entry 的文件夹范围内,或者依据模块的名称决定是否进行 trace。因此 EndPoint 赋予了我们自由选择 trace 深度的能力。
CodeGen 基于 AST 用于代码重构和生成,默认会将所有 trace 到的文件以其原有文件名生成在指定的同一层级目录下,并且重�写相关的 import,保证重新生成的文件可以正常运行。CodeGen 需要支持用户定义生成的文件层级结构,并自动地分析依赖关系,重写 import、移除未调用函数/类和变量等。目前仍没有很好的形式来支持用户自定义的功能。
分析 import
在分析依赖的过程中,首先获取 import 节点,在 python ast 中对应的类型为 Import 和 ImportFrom ,我们可以将 imoprt 类型分为以下四种类型:
- 从包/模块导入对象(类、函数、变量)
- 直接导入模块
- 从包/模块导入所有可导入对象(import *)
- 相对导入
对于 1,4 的情况,我们默认 trace 所有的导入对象(即不论有没有被使用),而对于 2,3 的情况,则需要对函数调用(Call)等进行分析之后才能进一步 trace。
对于直接导入模块的情况,需要找到形如 module.xxx() 或 getattr(module, 'xxx')() 等函数调用\类实例,或者非调用,如将函数存入字典进行映射, 不会显式地调用。获得具体的依赖对象名称,再进行 trace。
对于 from xxx import * 的情况,则记录下一些无主的 Call(即直接调用,并且不在已记录的 import 中)作为候选集,待到分析对应的文件时做分析。
此外还有以下非 Call 的情况,如使用模块的变量 module.xxx,需要另行处理。
分析 Call
在 python ast 中,函数调用、类实例化都对应着一个对象——Call ,但仍然存在着某些复杂情况难以分析,可以大致分为如下几类:
- 嵌套调用
- 回调函数
- 隐式调用
对于嵌套调用,一个复杂样例如下
self.xxx[0]['name']()
在此种情况下,若 self.xxx[0]['name'] 对应的对象为从包/模块直接导入的,则不会产生影响,若函数为以 getattr 的形式从 导入的模块/包中获取,则无法进行 trace。这种情况的解决方法见分析 import 中的直接导入模块情况。
ast 对于回调函数的解析会获得与原函数不同的 name,这会导致错误的 trace 失败,因此我们需要对 Call 的参数进行分析,判断其是否是 Callable 对象,若拥有回调函数的对象不在当前的范围内被调用,则无需处理。实际上回调函数应当算是隐式调用的一种特殊情况。
隐式调用的一个样例如下:
module_name = node.__class__.__name__
getattr(module, 'xxx_' + module_name)
对于此种情况可能需要保留 module 中的所有对象。
另外一种隐式调用的例子为:
from module import func1,func2, func3
a = func1
a()
mapper = {'1': func1, '2': func2, '3': func3}
mapper['1']()
虽然默认 trace 所有显式导入的对象可以解决这个问题,但是为了拓展去除无用变量的功能(这可能会在扁平化类继承中被用到),仍然需要进一步进行分析。
分析变量
为了解�决上述所提到 隐式调用 的问题,必须对此类赋值进行分析,如:
from module import func1, func2
func = func1 # value为Name
func_mapper = {'1': func1, '2', func2} # value为Dict
func_list = [func1, func2] # value为List
此类赋值会被 Python ast 解析为 Assgin ,其拥有 target 和 value 两个属性,然而 value 可能为 Name, Dict, List 等各种类型,因此最简单的方法便是直接分析解析出来的 AST 中的所有 Name 节点,当其名称已存在(已经导入/已经定义),则说明该节点所代表的变量被使用。最后将已使用的名称与定义和导入的名称进行对比即可得出已经使用的变量和未使用的变量。
分析属性
形如 module.func 的以 . 连接的字符串都会被解析为 Attribute 对象,可以在其 value 和 attr 属性中分别获得从 module 和 func,即可完成 trace。对于嵌套的形式 module.a.func,只需获得前两层即可,即 module.a。
其他
- 为了便于阅读,生成之后文件可能需要进行格式化。
- 某些情况重构依赖之后 import 可能会重复导入,需要去重。
打包最小工程
如上,对于 OpenMMLab 的算法库,需要通过给定的配置文件来得到入口文件,以进行打包。打包思路如上所示,不再赘述。
对于打包出来的结构可能需要进一步讨论,如是将所有文件放在同一层级,还是将 model, dataset, transform 等单独放置,仅将 train val infer 放在最外层。
为了跨项目进行调用,OpenMMLab 对 Register 进行了层级化的设计,因而可以通过配置文件调用不同模型库中的模块,这意味着入口文件可能不在本地的 scope 下,因此要求我们设置相应的 endpoint,将安装的其他算法库包含在 trace 的范围内。
代码生成则是另一个难点,通常来说,一个模型所依赖的文件十分之多,而本任务要求对这些文件进行分类,并最终合并到同一个文件中,例如 Model 中的 Backbone, Neck, Head 都来自于不同的文件,但最终生成的 model.py 文件应该包含了模型的全部组件。这要求本项目拥有自定义 CodeGen 的能力(目前尚未找到很好的方法),另一种思路是不同模块的文件单独进行 trace,如只先单独提取模型所涉及到的文件至 model.py,再处理 dataset 涉及到的文件。
简化继承关系
简化继承关系要求我们获得继承链,并从上至下的进行 patch 。对于 OpenMMLab 中的大部分类来说,所有基类基本上都可以追溯到 MMEngine 中,因此,我们可以 EndPoint 为条件,trace 至 MMEngine 则停止,将得到的所有继承关系进行合并,例如:
ExampleHead-> DynamicMaskHead -> FCNMaskHead -> BaseModule
实际上我们获得的继承链为
ExampleHead-> DynamicMaskHead -> FCNMaskHead
则我们从 ExampleHead 开始,逐步地向上合并,合并步骤为:
- 判断所有属性\方法是否在子类上,若在则不进行 patch,不在则进行 patch,若有一些特殊情况则另做处理。
- 一些特殊情况的处理。
- 改写子类继承自父类的父类(若有),没有则消除继承。
- 将父类的依赖添加至子类文件中。
- 移除父类,重新分析父类所在文件的依赖关系。
- 以如上方法不断进行两两合并,直至到最后一个子类,则合并结束。
类继承合并的过程中也有一些特殊情况的处理:
- 所有包含
super()的方法,需要以更细的级别进行 patch。 super()调用了非一级父类的方法,如ExampleHead中调用了super(DynamicMaskHead, self),即 ExampleHead 中调用的 DynamicHead 父类的方法,目前没有什么较好的处理方式,需要抛出异常。当然此类情况出现较少,初步浏览 OpenMMLab 算法库中的代码,尚未发现此类情况。- 引用了导入或者本地的对象,需要一并将依赖关系添加至子类的文件当中。
可读性方面,可能需要将 Patch 上的方法以一定的顺序进行排列,如 __init__, __new__ 等最好置于所有方法之前,静态方法、类方法在其他方法之前等。
将代码展开的 pytorch 级别
根据不同的应用需求,考虑了三种方案:
直接 trace
通过设置 EndPoint 和 CodeGen 可以将 MMEngine 中的相关代码(Registry 等)抽取出来,与上述使用并无区别,因此不再赘述。
消除 Registry、Config
然而出于对实际应用的考虑,这样 trace 出来的结果依旧,我们似乎并不需要什么配置系统和注册机制,而是需要更加原生的 pytorch 代码。
因此,我们需要消除 MM 系列套件中的静态注册器以及配置系统,总体思路如下:
-
移除所有类装饰器 register
-
build config 中的所有对象,如 Model、Optimizer 等,存入字典中,将 config 中的其他变量也存入字典
-
import 无需重构,因为打包最小工程也需要导入对应的模块。
-
改写 train, eval, infer 的命令行参数,不再接收 config 文件,固定训练参数。
消除 Runner、Hook
更进一步的,Runner/Hook(以及相应而生的 ManagerMix 等)的设计似乎对当前场景(单个模��型)来说有些 over-engineered,可以考虑将 Runner 改写为函数式,用户可以自由的修改代码逻辑,而无需理解 Runner、注册 Hook,从而进一步减少用户的心智负担。实现方法考虑如下:提前写好一份函数式的训练、验证和推理模板,功能保持与 Runner 一致,并且接收相同的参数。
总的来说,本项目的设计天然支持将代码展开的 PyTorch 级别,但是对于进一步简化代码,则需要付出更多努力。
五、期望
显然,按照上述设计思路,本项目不仅仅可以为 OpenMMLab 所用,只要设置好 Entry 和 EndPoint 等,任何深受其苦的开发套件都可以使用本项目达到相似的效果。希望本项目也可以为其他项目做出一份贡献,发扬开源精神。
同时,这是一个非常有挑战性和意义的项目,也是我第一次有机会能参与进 OpenMMLab 的社区,希望尽己所能,完成本项目,并在后续多多参与社区贡献。
六、测试和验收的考量
- 考虑到适配所有模型的工作量巨大,或许我们可以先适配一些经典常用的模型,对于一些 corner case 和 hard case 后续再逐渐进行适配。
- 尽可能简化生成文件,去除未使用变量,保证可读性良好。
- 需添加相关文档及单测。
七、排期规划
| 开始时间 | 结束时间 | 内容 |
|---|---|---|
| 06/15 | 06/30 | 与导师进一步讨论方案设计及细节实现。 |
| 07/01 | 07/15 | 完善整体设计,并进行实现。 |
| 07/15 | 08/15 | 整体编写完毕,测试常用模型,如 ResNet、YOLO 系列等。 |
| 08/15 | 活动结束 | 提交 PR 迭代优化直至 merge。 |
八、影响
本项目为添加新功能,仅在我可预见的实现中,不会对 MM 系列的其他模块产生修改或影响。