快速上手框架,从零复现论文——模型篇上
接上篇,本篇将会介绍 RepVGG 模型的复现过程,复现代码已开源,https://github.com/Asthestarsfalll/RepVGG-MegEngine。
阅读源码
在开始复现前,我们先简单的看一遍模型的代码,打开官方仓库中的 repvgg.py,梳理清楚网络的组成和层次:
ConvBn
代码中首先定义了一个 conv_bn,这是 RepVGG 的核心之一,训练完毕之后将会进行吸 Bn 的操作,即将 Bn 转化到 Conv 中去,不了解的可以看我之前的论文阅读笔记。代码如下:
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
RepVGGBlock
RepVGGBlock 由三个分支组成,分别是 3×3 卷积 +BN,1×1 卷积 +BN,和 Identity+BN 组成,如下图:
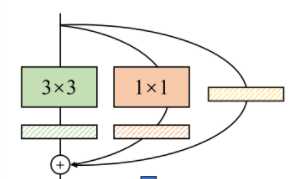
此外,RepVGGBlock 还会有一个 use_se 参数来决定是否使用通道注意力模块 SEBlock,对于其中的一些属性进行简单的讲解:
self.deploy表示网络所处的状态,训练时为 False,当进行重参数化之后会变为 True;padding_11表示 1×1 卷积所使用的 padding,实际上就是 0;- 当且仅当输入通道数等于输出通道数并且步长为 1 时,第三个分支才存在,其余情况不存在第三个分支;
RepVGGBlock 自身存在几个比较重要的方法:
_fuse_bn_tensor:该方法便是为了完成所谓的“吸 Bn”,公式推导见论文阅读笔记,一个比较重要的点是当 groups 不为 1 时会比较特殊,将在后续进行说明;get_equivalent_kernel_bias:该方法首先会调用_fuse_bn_tensor来得到融合过后的卷积核权重和偏置,然后将 1×1 的卷积核 zero padding 为 3×3,直接将所有的卷积核权重和偏�置分别相加便可以得到等效的 kernel 和 bias;switch_to_deploy:该方法用于训练完成后进行重参数化。
RepVGG
RepVGG 由 5 个 stage 组成,第一个 stage 只包含一个 RepVGGBlock,用来调整通道数,一些比较重要的参数和属性如下:
width_multiplier:控制每一个通道的宽度,后面 4 个 stage 的通道基数分别是 64,128,256,512;num_blocks:控制每个 stage 的 Block 的数量;override_groups_map:控制 Block 中的 groups 数;_make_stage:根据输入的参数来搭建各个 stage。
重参数化
使用了一个函数来进行重参数化:
def repvgg_model_convert(model:torch.nn.Module, save_path=None, do_copy=True):
if do_copy:
model = copy.deepcopy(model)
for module in model.modules():
if hasattr(module, 'switch_to_deploy'):
module.switch_to_deploy()
if save_path is not None:
torch.save(model.state_dict(), save_path)
return model
复现模型
对源码有了大概的了解,接下来开始模型的复现。
新建文件夹
习惯上,对于较为简单的项目,我将模型代码放在名为 model 的文件里,参考 官方代码 可知,model 里应该有如下文件:
|- model
|- __init__.py
|- repvgg.py
|- repvggplus.py
|- se_block.py
让我们首先开始最简单的部分——se_block.py
SEBlock
由于我们是刚上手 MegEngine 这个框架,因此我们的每一步都需要参考 官方文档,以确保绝对正确,代码如下:
class SEBlock(M.Module):
def __init__(self, input_channels, ratio: int = 16):
super(SEBlock, self).__init__()
internal_neurons = input_channels // ratio
assert internal_neurons > 0
self.gap = M.AdaptiveAvgPool2d((1, 1))
self.down = M.Conv2d(
in_channels=input_channels,
out_channels=internal_neurons,
kernel_size=1,
bias=True
)
self.relu = M.ReLU()
self.up = M.Conv2d(
in_channels=internal_neurons,
out_channels=input_channels,
kernel_size=1,
bias=True
)
self.sigmoid = M.Sigmoid()
def forward(self, inputs):
x = self.sigmoid(self.up(self.relu(self.down(self.gap(inputs)))))
return inputs * x
每次写完一个部分,我们都需要进行测试,来保证模型构建的准确无误:
if __name__ == "__main__":
se = SEBlock(64, 16)
a = mge.tensor(np.random.random((2, 64, 9, 9)))
a = se(a)
print(a.shape)
ConvBn
最初这里和源码一样,我使用的是 M.Sequential 来实现,但是其并没有 add_module 的方法,但是查看官方文档,发现它是可以使用 OrderedDict 来传入名字和对应的模块。
后来 megengine 官方发布了 RepVGG 的版本,我发现可以直接使用 M.ConvBn2d,实际上 pytorch 也存在 nn.ConvBn2d,可见 API 文档的重要性,能够省一些力气。
RepVGGBlock
这里的复现基本照抄稍作修改即可,不过在 zero padding 的时候出现了问题,当时 megengine 并未提供 padding 的算子,不过好在 padding 的情况不是很复杂,只需要创建一个 hw 为 3×3 的 tensor,其中心值赋值为对应的数即可,后续 1.6 版本支持了 F.nn.pad,代码如下:
def _zero_padding(self, weight):
if weight is None:
return 0
else:
# windows 1.6版本会报错,可使用以下代码
# kernel = F.zeros((*weight.shape[:-2], 3, 3), device=weight.device)
# kernel[..., 1:2, 1:2] = weight
kernel = F.nn.pad(
weight, [*[(0, 0) for i in range(weight.ndim - 2)], (1, 1), (1, 1)])
return kernel
抄完了剩下的代码之后我们需要进行验证,在主文件夹中新建一个verify.py专门用来验证模型的构建,验证过程中我选择尽量的一次性验证最多的情况,对于 RepVGGBlock 来说,即 use_se=Ture,groups=2,in_ch=out_ch,此外我还构建了一个分类器用于验证 switch_to_deploy 的正确与否,代码如下:
import megengine as mge
import megengine.functional as F
import numpy as np
import model as repvgg
class Classifier(mge.module.Module):
def __init__(self, planes):
super(Classifier, self).__init__()
self.downsample = mge.module.Conv2d(
in_channels=planes,
out_channels=planes,
kernel_size=3,
stride=2,
padding=1,
)
self.gap = mge.module.AdaptiveAvgPool2d((1, 1))
self.fc = mge.module.Linear(planes, 1000)
def forward(self, inputs):
out = self.downsample(inputs)
out = self.gap(out)
out = F.flatten(out, 1)
out = self.fc(out)
return out
def calDiff(out1, out2): # 用来验证输出结果
print('___________test diff____________')
print(out1.shape)
print(out2.shape)
print(F.argmax(out1, axis=1))
print(F.argmax(out2, axis=1))
print(((out1 - out2)**2).sum())
def verifyBlock():
print('___________RepVGGBlock____________')
inputs = mge.tensor(np.random.random((8, 16, 224, 224)))
block = repvgg.RepVGGBlock(in_ch=16, out_ch=16, stride=1,
groups=2, deploy=False, use_se=True)
downsampe = Classifier(16)
downsampe.eval()
block.eval()
out1 = downsampe(block(inputs))
print(block)
print('___________RepVGGBlock switch to deploy____________')
block.switch_to_deploy()
block.eval()
out2 = downsampe(block(inputs))
print(block)
calDiff(out1, out2)
if __name__ == '__main__':
verifyBlock()
没想到一运行就报错了,查看报错信息发现是吸 BN 的位置出错了,卷积核的形状有问题;
遇到这种问题千万不要慌张,打开官方文档一看,原来 MegEngine 的分组卷积的卷积核形状不同:

打开 PyTorch 的官方文档进行对比:

果然不一样,因此我们需要对代码进行修改,当 groups 不为 1 时,将 kernel reshape 为相应的形状,代码如下:
# self.groups_channel = in_ch % groups in_ch=out_ch
assert isinstance(branch, M.BatchNorm2d) # "self.identity"
if not hasattr(self, 'bn_identity'): # 对于BN层,初始化时创建一个bn_identity
# group convlution kernel shape:
# [groups, out_channels // groups, in_channels // groups, kernel_size, kernel_size]
kernel_value = np.zeros(
(self.groups_channel * self.groups, self.groups_channel, 3, 3), dtype=np.float32)
for i in range(self.groups_channel * self.groups): # out_channels
kernel_value[i, i % self.groups_channel, 1, 1] = 1
if self.groups > 1:
kernel_value = kernel_value.reshape(
self.groups, self.groups_channel, self.groups_channel, 3, 3)
self.bn_identity = mge.Parameter(kernel_value)
修改完之后代码确实能跑通了,但是结果仍然有问题——switch_to_deploy 之后分类器的结果不同,经过再三 debug 发现是赋值代码有问题:
self.reparam.weight.data = kernel
self.reparam.bias.data = bias
MegEngine 中不支持。data,因此改为深拷贝:
self.reparam.weight[:] = kernel
self.reparam.bias[:] = bias
RepVGG
剩下的部分直接根据官方文档照搬照抄即可,没有什么需要注意的点,在复现完毕后,同样需要写验证代码,在上文中的verify.py中再添加如下代码:
def verifyRepVGG(model_name, state_dict=None):
print(f'___________{model_name}____________')
inputs = mge.tensor(np.random.random((2, 3, 224, 224)))
model = repvgg.__dict__[model_name](False)
if state_dict is not None:
model.load_state_dict(state_dict)
model.eval()
out1 = model(inputs)
print(f'___________{model_name} switch to deploy____________')
model._switch_to_deploy_and_save('./ckpt', 'test')
model.eval()
out2 = model(inputs)
calDiff(out1, out2)
经过检验没什么问题,至此 repvgg.py 和 se_block.py 算是复现完了,repvgg_plus.py 留在下节介绍。