分布式训练从入门到放弃
为什么要使用分布式训练
随着数据集体积的不断扩大,动辄 TB 甚至是 PB 的数据量使得单卡训练成为幻影,即使对于普通的数据集和模型,更快的速度,更大的显存,更高的显卡利用率,以及更大的 batchsize 带来更好的性能也都是我们所追求的。
一些分布式训练算法
所谓分布式,指的是计算节点之间不共享内存,需要通过网络通信的方式交换数据,以下介绍几种不同的分布式训练算法。
Spark MLlib
Spark 的分布式计算原理:
首先需要了解一下 Spark 分布式计算原理
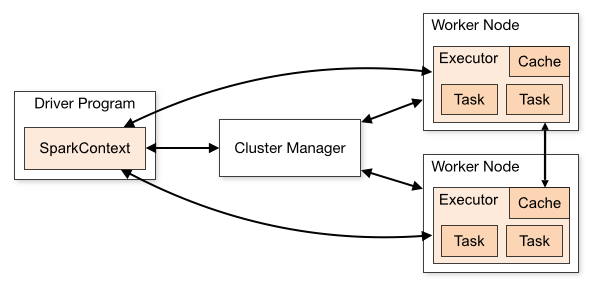
额,没太看懂,大概就是
-
**Driver:**创建 SparkContext,来提供程序运行所需要的环境,并且负责与 Cluster Manager 进行通信来实现资源申请、任务分配和监控等功能,当 Executor 关闭时,Driver 同时将 SparkContext 关闭;
-
**Executor:**工作节点(Worker Node)中的一个进程,负责运行 Task;
-
**Task:**运行在 Executor 上的工作单元;
-
**RDD:**弹性分布式数据集,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型,其具有以下性质:
- 只读不能修改,只能通过转换生成新的 RDD;
- 可以分布在多台机器上并行处理;
- 弹性:计算中内存不够会和磁盘进行数据交换;
- 基于内存:可以全部或部分缓存在内存中,在多次计算间重用。
-
**partition:**RDD 基础处理单元是 partition(分区),一个 Work Node 中有多个 partition,每个 partition 的计算都在一个不同的 task 中进行
-
**DAG:**有向无环图,反映 RDD 之间的依赖关系,在执行具体任务之前,Spark 会将程序拆解成一个任务 DAG;处理 DAG 最关键的过程是找到哪些是可以并行处理的部分,哪些是必须 shuffle 和 reduce 的部分。
-
**shuffle:**指的是所有 partition 的数据必须进行洗牌后才能得到下一步的数据
-
**Job:**一个 Job 包含多个 RDD 及作用于相应 RDD 上的各种操作;
-
**Stage:**是 Job 的基本调度单位,一个 Job 会分为多组 Task,每组 Task 被称为 Stage,或者也被称为 TaskSet,代表一组关联的,相互之间没有 Shuffle 依赖关系的任务组成的任务集;
-
**Cluter Manager:**指的是在集群上获取资源的外部服务。目前有三种类型
- Standalon : spark 原生的资源管理,由 Master 负责资源的分配;
- Apache Mesos: 与 hadoop MR 兼容性良好的一种资源调度框架;
- Hadoop Yarn: 主要是指 Yarn 中的 ResourceManager。
Spark MLlib 并行训练原理:
简单的数据并行,缺点如下:
- 采用全局广播的方式,在每轮迭代前广播全部模型参数。
- **采用阻断式的梯度下降方式,每轮梯度下降由最慢的节点决定。**Spark 等待所有节点计算完梯度之后再进行汇总。
- Spark MLlib 并不支持复杂网络结构和大量可调超参,对深度学习支持较弱。
Parameter Server
Parameter Server 由李沐大佬提出,如今已被各个框架应用于分布式训练当中。论文地址
在分布式训练当中,输入数据、模型、反向传播计算梯度都是可以并行的,但是更新参数依赖于所有的训练样本的梯度,这是不能并行的,如下图所示:

Parameter Server 包含一个参数(server)服务器(或者 GPU 等)来复制分发model到各个工作(worker)服务器上,计算示意图如下:
.drawio%20(1).svg)
- 将数据和初始化参数加载到 server 当中,若无法一次加载进来也可分多次加载;
- server 将输入数据进行切片,分发给各个的 worker;
- server 复制模型,传递给各个 worker;
- 各个 worker 并行进行计算(forward 和 backward);
- 将各个 worker 求得的梯度求平均,返�回 server 进行更新(push:worker 将计算的梯度传送给 server),同时回到第二步,重新分发更新过后的模型参数(pull:worker 从 server 拉取参数)。
通过上图可以看到每个 worker 之间没有任何信息交换,它们都只与 server 通信。
上述过程貌似和 Spark 差不多,实际上 PS 中的 server 和 worker 中存在很多节点,它们分别组成server group和worker group,功能与上述基本一致,对于 server group,存在server manager来维护和分配各个 server node 的数据,如下图所示:

缺点:
上文提到的 Spark 使用的是同步阻断的方式进行更新,只有等所有节点的梯度计算完成后才能进行参数更新,会浪费大量时间;
对此,PS 使用了异步非阻断的方式进行更新,当某个 worker 节点完成了 push 之后,其他节点没有进行 push,这表示该节点无法进行 pull 来拉取新模型,此时该节点会直接再次进行计算,并且将当次计算的梯度在下一次 push 提交给 server。
这种取舍虽然使得训练速度大幅增加,但是却造成模型的一致性有所丧失,具体影响还是有待讨论。
该方法可以通过最大延迟来限制这种异步操作,即某个 worker 节点最多只能超过 server 几轮迭代,超过之后必须停下来等待 pull。
多 server 节点的协同和效率问题:
Spark 效率低下的另一个原因是每次更新参数之后都需要使用单个 master 节点将模型参数广播至各个 worker 节点;
由于 Parameter Server 使用了多 server node 结构的 server group,每个 server node 负责模型参数中的 K-V 对,并行地进行数据传播,大大加快了速度;
使用哈希一致性来保证每个 server node 负责对应的 key range,并且能保证已有 key range 变化不大的情况下添加新的节点(看不懂)
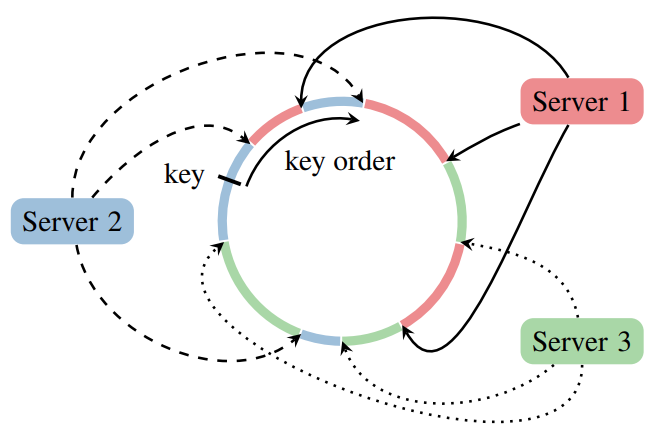
Ring AllReduce
摒弃了使用 server 来进行输入传输,而是将各个 worker 连成环,进行循环传递来达到“混合”的效果,主要流程:
- 对于 N 个 worker,将其连成一个环,并且将每个 worker 中的梯度分成 N 份;
- 对于第 k 个 worker,其会将第 k 份梯度发送给下一个节点,同时从前一个节点收到第 k-1 份梯度;
- 将收到的 k-1 份梯度和原有的梯度整合,循环 N 次,这样每个节点都会包含所有节点梯度的对应的一份;
- 每个 worker 再将整合好的梯度发给下一个 worker 即可,需要注意的是,这里直接使用前一个 worker 的梯度覆盖当前的梯度,依然循环 N 次。
- 最后每个 worker 都会得到所有梯度,除以 N 即可进行参数更新。
更多算法请看 此
NCCL
NCCL 是 Nvidia Collective multi-GPU Communication Library 的简称,它是一个实现多 GPU 的 collective.
pytorch code
pytorch 的分布式训练目前仅支持 linux 系统。
pytorch 数据分布式训练类型主要有:
- **单机单卡:**最简单的训练类型;
- **单机多卡:**代码改动较少;
- **多机多卡:**多台机器上的多张显卡,机制较为复杂;
- **其他:**其他的一些情况,不介绍。
DataParallel
单机多卡的情况,代码改动较少,主要基于 nn.DataParallel,是一种 单进程多线程 的训练方式,存在 GIL 冲突。
torch.nn.DataParallel 定义如下:
class torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
包含三个参数:
- module:表示需要 Parallel 的模型,实际上最终得到的是一个
nn.Module - device_ids:表示训练用 GPU 的编号
- output_device:表示输出的 device,用于汇总梯度和参数更新,默认选择 0 卡
- dim:表示处理 loss 的维度,默认 0 表示在 batch 上处理,使用了多少 GPU 就会返回多少个 loss
不想使用 0 卡可以用如下方式指定训练设备
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" # 表示按照PCI_BUS_ID顺序从0开始排列GPU设备,不使用指定多卡时会报错
os.environ["CUDA_VISIBLE_DEVICES"] = "2, 3" # -1表示禁用GPU
训练代码为:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
if torch.cuda.device_count()>1:
model = nn.DataParallel(model)
model.to(device)
更优雅点可以这样:
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model,device_ids=range(torch.cuda.device_count())) # 直接全用
也可以使用如下方式指定训练 GPU:
device_ids = [2, 3]
net = torch.nn.DataParallel(net, device_ids=device_ids)
机制很简单,即将模型复制到各个 GPU 上进行 forward 和 backward,由 server 卡汇总计算平均梯度,再分发更新后的参数至各个 worker。这就导致了一个问题——负载不均衡,server 卡的占用会很高,其原因主要是在 server 上计算 loss,可以在每个 gpu 上计算 loss 之后返回给 server 求平均。
在保存和加载模型时
# 保存模型需要使用。module
torch.save(net.module.state_dict(), path)
# 或者
torch.save(net.module, path)
# 正常加载模型
net.load_state_dict(torch.load(path))
# 或者
net = torch.load(path)
另一个需要注意的点是,使用 DataParallel 时的 batch_size 表示总的 batch_size,每个 GPU 上会分到 n 分之一。
DistributedDataParallel
多机多卡的训练方式,多进程 不存在 GIL 冲突,也适用于单机单卡,并且速度较快。
DistributedDataParallel 需要��一个 init_process_group 的步骤来启动
class torch.distributed.init_process_group(backend,
init_method=None,
timeout=datetime.timedelta(0, 1800),
world_size=-1,
rank=-1,
store=None)
- backend:str:gloo,mpi,nccl 。指定当前要使用的通信后端,通常使用 nccl;
- init_method:指定当前进程组的初始化方式;
- timeout:指定每个进程的超时时间,��仅可用于 "gloo" 后端;
- world_size:总进程数;
- store:所有
worker可访问的key/value,用于交换连接 / 地址信息。与init_method互斥。
其他函数:
torch.distributed.get_backend(group=group) # group是可选参数,返回字符串表示的后端 group表示的是ProcessGroup类
torch.distributed.get_rank(group=group) # group是可选参数,返回int,执行该脚本的进程的rank
torch.distributed.get_world_size(group=group) # group是可选参数,返回全局的整个的进程数
torch.distributed.is_initialized() # 判断该进程是否已经初始化
torch.distributed.is_mpi_avaiable() # 判断MPI是否可用
torch.distributed.is_nccl_avaiable() # 判断nccl是否可用
简单的使用:
初始化
torch.distributed.init_process_group(backend='nccl', init_method='env://')
DistributedSampler:
注意这里与 DataParallel 不同,batch_size 的大小表示每个 GPU 上的大小,需要将 dataloader 切分。
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data)
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=False,
num_workers=2, pin_memory=True, sampler=train_sampler,)
这里需要设置 shuffle=False,然后在每个 epoch 前,通过调用 train_sampler.set_epoch(epoch) 来达到 shuffle 的效果。
模型的初始化:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
同步 BN:
BN 层对于较大的 batch_size 有更好的性能,所以对于 BN 需要使用所有卡上的数据来进行计算。
使用 Apex:
from apex.parallel import convert_syncbn_model
from apex.parallel import DistributedDataParallel
# 注意顺序:三个顺序不能错
model = convert_syncbn_model(UNet3d(n_channels=1, n_classes=1)).to(device)
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
model = DistributedDataParallel(model, delay_allreduce=True)
或者使用 这里 的代码来代替 nn.BatchNorm
训练:
提供了 torch.distributed.launch 用于启动训练
export CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 train.py
nproc_per_node 参数指定为当前主机创建的进程数。一般设定为当前主机的 GPU 数量
模板:
import torch.distributed as dist
import torch.utils.data.distributed
# ......
parser = argparse.ArgumentParser(description='PyTorch distributed training on cifar-10')
parser.add_argument('--rank', default=0,
help='rank of current process')
parser.add_argument('--word_size', default=2,
help="word size")
parser.add_argument('--init_method', default='tcp://127.0.0.1:23456',
help="init-method")
args = parser.parse_args()
# ......
dist.init_process_group(backend='nccl', init_method=args.init_method, rank=args.rank, world_size=args.word_size)
# ......
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=download, transform=transform)
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, sampler=train_sampler)
# ......
net = Net()
net = net.cuda()
net = torch.nn.parallel.DistributedDataParallel(net)