CUDA 线程编程
在本文中我们将探讨 CUDA 的分层线程架构,这一架构使我们能够以组的形式管理 CUDA 线程,从而更好地控制 GPU 资源,实现高效的并行计算。
首先,让我们来了解 CUDA 线程的操作方式。在 GPU 上,线程可以以并行和并发的方式执行,形成所谓的 " 线程组 "。这些线程组以 warp 的形式执行,利用内存带宽,同时处理控制开销和实现 SIMD(Single Instruction, Multiple Data)操作,以提高计算效率。
- 分层 CUDA 线程操作
- 了解 CUDA 占用率
- 在多个 CUDA 线程之间共享数据
- 识别应用程序性能瓶颈
- 最小化 CUDA warp 分歧效应
- 提高内存利用率和网格跨距循环
- 利用协作组来灵活处理线程
- Warp 同步编程
- 低/混合精度操作
CUDA 的线程和块
在 CUDA 编程中,CUDA 线程、线程块和 GPU 是基本的工作单位。CUDA 编程的基本线程执行模型是单指令多线程(SIMT)模型。换句话说,核函数的主体是单个 CUDA 线程的工作描述。但是,CUDA 架构会执行多个具有相同操作的 CUDA 线程。从概念上讲,多个 CUDA 线程在组内并行工作。CUDA 线程块是多个 CUDA 线程的集合,多个线程块可以并发运行。我们将一组线程块称为一个网格。以下图表显示了它们之间的关系:
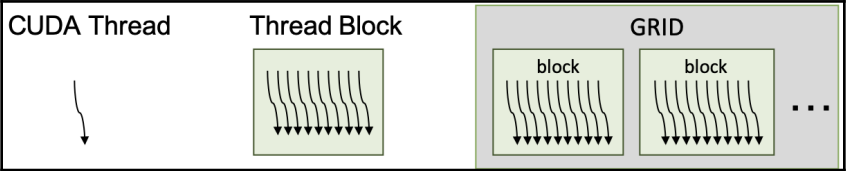
这些分层的 CUDA 线程操作与分层的 CUDA 架构相匹配。当我们启动一个 CUDA 核函数时,在 GPU 的每个多流处理器上执行一个或多个 CUDA 线程块。此外,多流处理器可以根据资源可用性运行多个线程块。线程块中的线程数和网格中的线程块数都会有所变化:
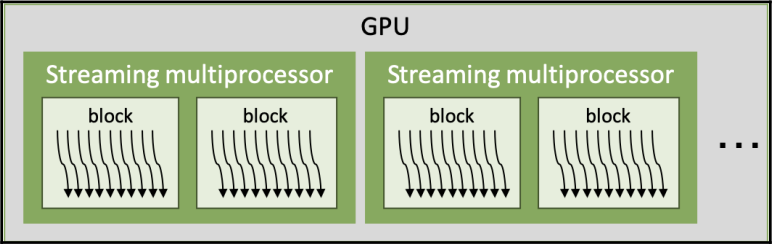
多流处理器以任意且并行的方式执行线程块,执行尽量多的线程块,以充分利用 GPU 资源��。因此,可以并行执行的线程块数量会根据线程块所需的 GPU 资源和 GPU 资源的数量而变化。我们将在下一节中详细讨论这一点。多流处理器的数量取决于 GPU 的规格。例如,对于 Tesla V100,它是 80,而对于 RTX 2080(Ti),它是 48。
CUDA 多流处理器以 32 个 CUDA 线程组成的一组来控制 CUDA 线程。这个组称为 warp(线程束)。一个或多个 warp 组成一个 CUDA 线程块。以下图表显示了它们之间的关系:

小的绿色框代表 CUDA 线程,它们由 warp 组成。warp 是 GPU 架构的基本控制单元,因此其大小会隐式或明确地影响 CUDA 编程。例如,最佳的线程块大小是在多个 warp 大小中确定的,这些大小可以充分利用线程块的 warp 调度和操作。我们称之为 " 占用率 ",这将在下一节中详细介绍。此外,warp 中的 CUDA 线程是并行工作的,并且具有同步操作,这是内在的。我们将在 " 线程束级别基元编程 " 部分讨论这一点。
现在,让我们看一下 CUDA 线程调度以及它们的隐式同步,使用 CUDA 的 printf 功能。并行 CUDA 线程的执行和线程块的操作是并行进行的。另一方面,从设备中打印输出是一个顺序任务。因此,我们可以很容易地看出它们的执行顺序,因为对于并行任务来说输出是任意的,对于并行任务来说输出是一致的。
我们将编写一个内核代码,用于打印全局线程索引、线程块索引、warp 索引和通道索引。为此,代码可以编写如下:
__global__ void index_print_kernel() {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int warp_idx = threadIdx.x / warpSize;
int lane_idx = threadIdx.x & (warpSize - 1);
if ((lane_idx & (warpSize/2 - 1)) == 0)
printf(" %5d\t%5d\t %2d\t%2d\n", idx, blockIdx.x,
warp_idx, lane_idx);
}
这段代码将帮助我们理解 warp 和 CUDA 线程调度的并发性。让我们编写调用内核函数的主机代码:
int main() {
int gridDim = 4, blockDim = 128;
puts("thread, block, warp, lane");
index_print_kernel<<< gridDim, blockDim >>>();
cudaDeviceSynchronize();
}
最后,让我们编译代码,执行它,并查看结果:
nvcc -m64 -o cuda_thread_block cuda_thread_block.cu
以下结果是输出结果的一个示例。实际输出可能会有所不同:
$ ./cuda_thread_block.cu 4 128
thread, block, warp, lane
64 0 2 0
80 0 2 16
96 0 3 0
...
112 0 3 16
0 0 0 0
16 0 0 16
...
352 2 3 0
368 2 3 16
288 2 1 0
304 2 1 16
从结果中,您将看到 CUDA 线程以 warp 大小启动,顺序是不确定的。另一方面,通道输出是有序的。根据结果,可得如下内容:
- 无序的线程块执行:第二列显示了线程块的索引。结果表明,不保证按照块索引的顺序执行。
- 具有线程块的无序 warp 索引:第三列显示了块中 warp 的索引。warp 的顺序在不同的块中变化。因此,我们可以推断没有 warp 执行顺序的保证。
- 在 warp 中以组的方式执行线程:第四列显示了 warp 中的通道。�为了减少输出的数量,应用程序将其限制为仅打印两个索引。从每个 warp 内的有序输出中,我们可以推断 printf 函数的输出顺序是固定的,因此没有反转。
总结一下,CUDA 线程分为 32 个线程一组,它们的输出和 warp 的执行没有顺序。因此,在进行 CUDA kernel 开发时必须记住这一点。
CUDA 占用率
CUDA 的占用率是活动CUDA 线程束与每个多流处理器同时执行的最大线程束之比。一般来说,更高的占用率也就意味着 GPU 的更有效利用,因为更多的线程束可用来隐藏停滞线程束的延迟。然而,这也可能会降低性能,因为 CUDA 线程之间的资源竞争增加。因此,权衡是至关重要的。
找到最佳的 CUDA 占用率的目的是使 GPU 应用程序有效地发出 GPU 资源的线程束指令。GPU 使用多个线程束调度程序在流多处理器上调度多个线程束。当多个线程束有效地调度时,GPU 可以隐藏 GPU 指令或内存延迟之间的延迟。然后,CUDA 核心可以执行连续从多个线程束发出的指令,而未调度的线程束必须等待能够发出下一个指令。
有两种方法确定 CUDA 占用率:
- CUDA Occupancy Calculator 确定的理论占用率:这个计算器是 CUDA Toolkit 提供的一个 Excel 表。我们可以从内核资源使用和 GPU 的流多处理器中理论上确定每个内核的占用率。
- GPU 确定的实际占用率:实际占用率反映了多流处理器上同时执行的线程束数和最大可用线程束数。可以通过 NVIDIA 性能分析器进行度量分析来测量此占用率。
理论占用率可以被视为最大的上限占用率,因为占用率数值不考虑��指令依赖性或内存带宽限制。
现在,让我们看看占用率和 CUDA C/C++ 的关系。
使用 NVCC 输出 GPU 资源使用情况
首先,我们将使用简单的矩阵乘法(SGEMM)内核代码,如下所示:
__global__ void sgemm_gpu_kernel(const float *A, const float *B,
float *C, int N, int M, int K, alpha, float beta) {
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
float sum = 0.f;
for (int i = 0; i < K; ++i) {
sum += A[row * K + i] * B[i * K + col];
}
C[row * M + col] = alpha * sum + beta * C[row * M + col];
}
然后,我们将使用以下内核代码调用内核函数:
void sgemm_gpu(const float *A, const float *B, float *C,
int N, int M, int K, float alpha, float beta) {
dim3 dimBlock(BLOCK_DIM, BLOCK_DIM);
dim3 dimGrid(M / dimBlock.x, N / dimBlock.y);
sgemm_gpu_kernel<<< dimGrid, dimBlock >>>(A, B, C, N, M, K, alpha,
beta);
}
我们将 N、M 和 K 设置为 2048,BLOCK_DIM 设置为 16。
现在,让我们看看如何使 nvcc 编译器报告内核函数的 GPU 资源使用情况。
在 Linux 环境中,我们应提供两个编译器选项,如下所示:
--resource-usage (--res-usage):为GPU资源使用设置详细选项
-gencode:指定要编译和生成操作码的目标架构,如下所示:
- Turing:compute_75, sm_75
- Volta:compute_70, sm_70
- Pascal:compute_60, sm_60, compute_61, sm_61
如果不确定正在使用哪个架构,可以从 CUDA GPU 网站上找到(https://developer.nvidia.com/cuda-gpus)。例如,nvcc 编译命令可以具有以下编译选项:
$ nvcc -m 64 --resource-usage \
-gencode arch=compute_70,code=sm_70 \
-I/usr/local/cuda/samples/common/inc \
-o sgemm ./sgemm.cu
我们还可以编译代码以针对多个 GPU 架构进行目标设定,如下所示:
$ nvcc -m64 --resource-usage \
-gencode arch=compute_70,code=sm_70 \
-gencode arch=compute_75,code=sm_75 \
-I/usr/local/cuda/samples/common/inc \
-o sgemm ./sgemm.cu
如果要使您的代码与新的 GPU 架构(Turing)兼容,您需要提供以下附加选项:
$ nvcc -m64 --resource-usage \
-gencode arch=compute_70,code=sm_70 \
-gencode arch=compute_75,code=sm_75 \
-gencode arch=compute_75,code=compute_75 \
-I/usr/local/cuda/samples/common/inc \
-o sgemm ./sgemm.cu
现在,让我们编译源代码。我们可以从 NVCC 的输出中找到资源使用情况报告。以下结果是使用前述命令生成的:

在上述输出屏幕截图中,我们可以看到每个线程的寄存器数量和常量内存使用情况。
占用率调优 - 限制寄存器使用
当内核的算法复杂或处理的数据类型是双精度时,CUDA 寄存器的使用可能会增加。在这种情况下,占用率会下降,因为活动线程束的大小受限。为了提高理论占用率并观察性能是否得到提升,我��们可以限制寄存器的使用。
在调整 GPU 资源使用时,一种方法是在内核函数中使用 __launch_bound__ 限定符。__launch_bound__ 限定符会限制最大块大小和最小线程块数。如果在编译时知道使算法高效运行所需的最大块大小和最小线程块数,可以使用这一选项(实际上这个东西好像没啥人用)。代码示例如下:
int maxThreadPerBlock = 256;
int minBlocksPerMultiprocessor = 2;
__global__ void
__launch_bound__(maxThreadPerBlock, minBlocksPerMultiprocessor)
foo_kernel() {
...
}
并行规约
规约 reduction 是一种简单但实用的算法,用于获得多个参��数之间的共同参数。这项任务可以按顺序或并行执行。在涉及到并行处理到并行架构时,并行规约是获取直方图、均值或其他统计值的最快方式。
以下图表展示了顺序规约和并行规约之间的差异:
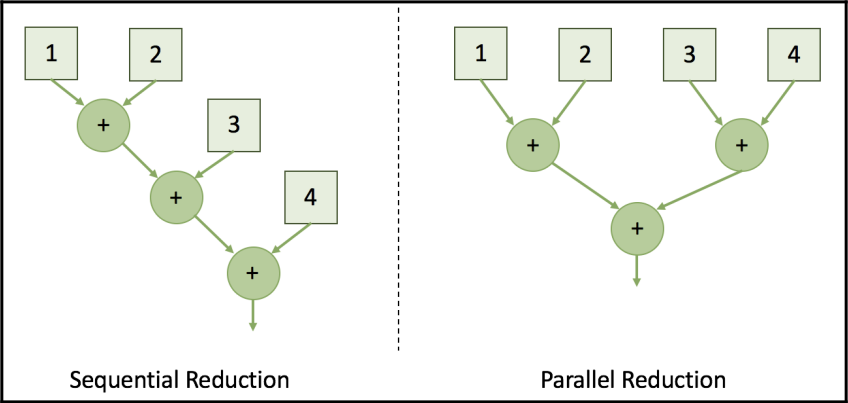
规约 "(reduction)是指一种算法,用于从一组参数中计算出一个共同的结果或值。这个共同的结果通常是通过将输入参数进行某种操作(例如求和、求平均值、获得直方图等)得到的。规约算法可以用于在并行计算中从多个输入参数中获取单个输出值,而且可以在顺序或并行计算中执行。
通过将规约任务并行执行,可以将总步骤数量降低到对数级别。现在,让我们开始在 GPU 上实现这个并行规约算法。首先,我们将使用全局内存实现一个简单设计。然后,我们将实现另一个使用共享内存的规约版本。通过比较这两种实现,我们将讨论性能差异是由什么引起的。
使用全局内存的规约
规约计算的第一个基本方法是使用并行的 CUDA 线程,并通过全局内存共享规约计算结果。对于每次迭代,CUDA 核心通过将其大小减小一半,从全局内存中获取累积值。下图显示了在全局内存数据共享的情况下进行的朴素并行规约计算:

然而,在 CUDA 中,这种方法速度较慢,因为它浪费了全局内存的带宽,没有充分利用更快的 on-chip 内存。为了获得更好的性能,建议使用共享内存来节省全局内存带宽并减少内存提取延迟。稍后,我们将讨论这种方法如何浪费带宽。
现在,让我们来实现这个规约计算。首先,我们将编写规约计算的核心函数,如下所示:
__global__ void naive_reduction_kernel(float *data_out, float *data_in, int stride, int size) {
int idx_x = blockIdx.x * blockDim.x + threadIdx.x;
if (idx_x + stride < size)
data_out[idx_x] += data_in[idx_x + stride];
}
我们将在不断减小步长大小的情况下迭代调用核心函数,直到步长大小为 1,如下所示:
void naive_reduction(float *d_out, float *d_in, int n_threads, int size) {
int n_blocks = (size + n_threads - 1) / n_threads;
for (int stride = 1; stride < size; stride *= 2)
naive_reduction_kernel<<<n_blocks, n_threads>>>(d_out, d_in, stride, size);
}
在这个实现中,核心代码通过跨步地址寻址从设备内存中提取数据,并输出一个规约计算的结果。主机代码触发每一步的规约计算核心,并参数大小减小一半。由于 CUDA 不能保证线程块和多流处理器之间的操作同步,所以我们无法在内部 Kernel 中使用循环。
使用共享内存的规约
在优化并行规约计算时,共享内存是一个关键概念,它可以显著提高性能。接下来,我们将讨论如何有效使用共享内存来改进规约计算性能。
在这个规约操作中,每个 CUDA 线程块对输入值进行规约,CUDA 线程使用共享内存共享数据。为了进行适当的数据更新,它们使用块级内在同步函数 __syncthreads()。然后,下一个迭代操作基于先前的规约结果。其设计如下图所示,显示了使用共享内存的并行规约:
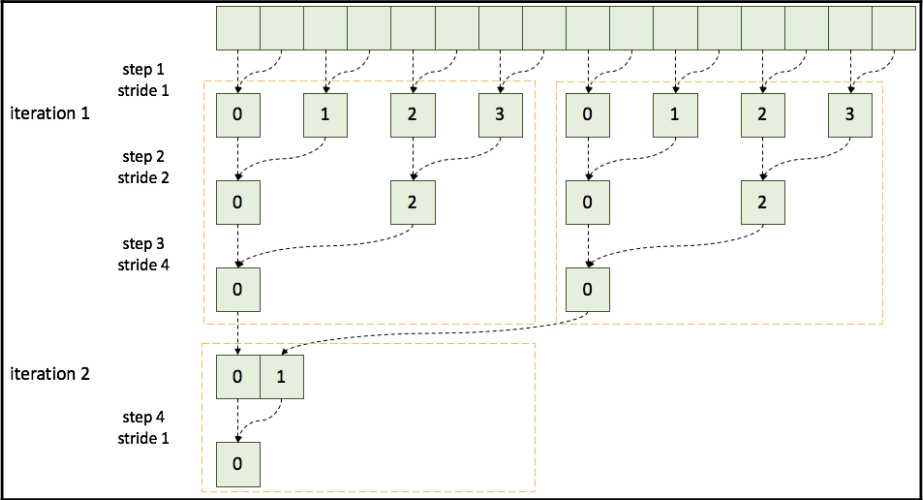
黄色虚线框表示了 CUDA 线程块的操作范围。在这个设计中,每个 CUDA 线程块输出一个规约结果。
块级规约允许每个 CUDA 线程块进行规约并输出单个规约输出。因为它不需要我们在全局内存中保存中间结果,CUDA 内核可以将过渡值存储在共享内存中。这个设计有助于节省全局内存带宽并减少内存延迟。
接下来,我们将编写内核函数,如下所示:
__global__ void reduction_kernel(float* d_out, float* d_in,
unsigned int size) {
unsigned int idx_x = blockIdx.x * blockDim.x + threadIdx.x;
extern __shared__ float s_data[];
s_data[threadIdx.x] = (idx_x < size) ? d_in[idx_x] : 0.f;
__syncthreads();
// 进行规约
for (unsigned int stride = 1; stride < blockDim.x; stride *= 2) {
// 线程同步规约
if ( (idx_x % (stride * 2)) == 0 )
s_data[threadIdx.x] += s_data[threadIdx.x + stride];
__syncthreads();
}
if (threadIdx.x == 0)
d_out[blockIdx.x] = s_data[0];
}
然后,我们将调用内核函数,如下所示:
void reduction(float *d_out, float *d_in, int n_threads, int size)
{
cudaMemcpy(d_out, d_in, size * sizeof(float),
cudaMemcpyDeviceToDevice);
while(size > 1) {
int n_blocks = (size + n_threads - 1) / n_threads;
reduction_kernel
<<< n_blocks, n_threads, n_threads * sizeof(float), 0 >>>
(d_out, d_out, size);
size = n_blocks;
}
}
在这段代码中,我们提供了 n_threads * sizeof (float) 字节,因为每个 CUDA 线程将共享每个字节的一个变量。这有助于更好地理解并行规约操作的实现过程。分配足够大的内存是为了确保每个线程能够安全地存储和访问共享的数据,以便进行并行规约操作。如果不提供足够的内存,代码可能会崩溃。
比较两种规约实现
为了比较两种规约实现的性能,我们将使用以下代码调用两个规约函数:
// 初始化计时器
StopWatchInterface *timer;
sdkCreateTimer(&timer);
sdkStartTimer(&timer);
... 执行代码 ...
// 获取经过的时间
cudaDeviceSynchronize(); // 阻塞主机,直到GPU完成工作
sdkStopTimer(&timer);
// 获取执行时间(微秒)
float execution_time_ms = sdkGetTimerValue(&timer)
// 终止计时器
sdkDeleteTimer(&timer);
现在,我们可以比较两个并行规约操作的执行时间。性能可能会根据 GPU 和实现环境的不同而有所变化。分别运行以下命令进行全局规约和使用共享内存的规约操作:
# 使用全局内存进行规约
$ nvcc -run -m64 -gencode arch=compute_70,code=sm_70 -I /usr/local/cuda/samples/common/inc -o reduction_global
./reduction_global.cpp reduction_global_kernel.cu
# 使用共享内存进行规约
$ nvcc -run -m64 -gencode arch=compute_70,code=sm_70 -I /usr/local/cuda/samples/common/inc -o reduction_shared
./reduction_shared.cpp reduction_shared_kernel.cu
使用我的 Tesla V100 PCIe 卡,两种规约操作的估计性能如下。元素数量为 :
| 操作方式 | 估计时间(毫秒) | 加速比 |
|---|---|---|
| 原始方法(使用全局内存规约) | 4.609 | 1.0x |
| 使用共享内存进行规约 | 0.624 | 7.4x |
从这个结果可以看出,使用共享内存的规约操作速度非常快。第一个实现版本位于 global_reduction.cu 中,第二个版本位于 shared_reduction.cu 中(位于书本的 git 仓库中)。
通过将规约操作与共享内存相结合,我们显著提高了性能。然而,我们不能确定这是我们可以获得的最大性能,也不清楚我们的应用程序存在什么瓶颈。为了分析这一点,我们将在下一部分中讨论性能限制因素。
减少 CUDA 线程的分歧效应
在单指令多线程(SIMT)执行模型中,线程被分为 32 个一组,每组称为一个 warp。如果一个 warp 遇到条件语句或分支,它的线程可能会分散并串行执行每个条件。这被称为分支分歧,对性能有显著影响。
下图展示了 CUDA 线程分歧效应。不在空闲状态的 CUDA 线程会降低 GPU 线程的有效利用率。随着分支部分的增多,GPU 调度吞吐量变得低效。因此,我们需要避免或减少这种 warp 分歧效应。我们可以选择以下几种选项:
- 通过处理不同 warp 来执行分支部分以避免分歧
- 对分支部分进行协同访问以减少 warp 中的分支
- 缩短分支部分,仅保留关键部分进行分支
- 重新排列数据(例如,转置、协同访问等)
- 使用协作组中的 tiled_partition 对组进行分区
- 将分歧视为性能瓶颈
将分歧视为性能瓶颈
从前面的优化中,我们会发现有关计算分析中分歧分支引发的不高效内核警告,如下所示:

73.4% 意味着我们的操作路径并不高效。我们可以确定分歧地址是问题,也就是代码中的 if 语句:
if ( (idx_x % (stride * 2)) == 0 )
s_data[threadIdx.x] += s_data[threadIdx.x + stride];
当涉及到减少地址分歧时,我们可以选择其中一种 CUDA 线程索引策略:
- 交织式寻址
- 顺序寻址
交织式寻址
在这种策略中,连续的 CUDA 线程使用交织寻址策略获取输入数据。与之前的版本相比,CUDA 线程通过增加步幅值来访问输入数据。以下图展示了 CUDA 线程如何与减少项交织:
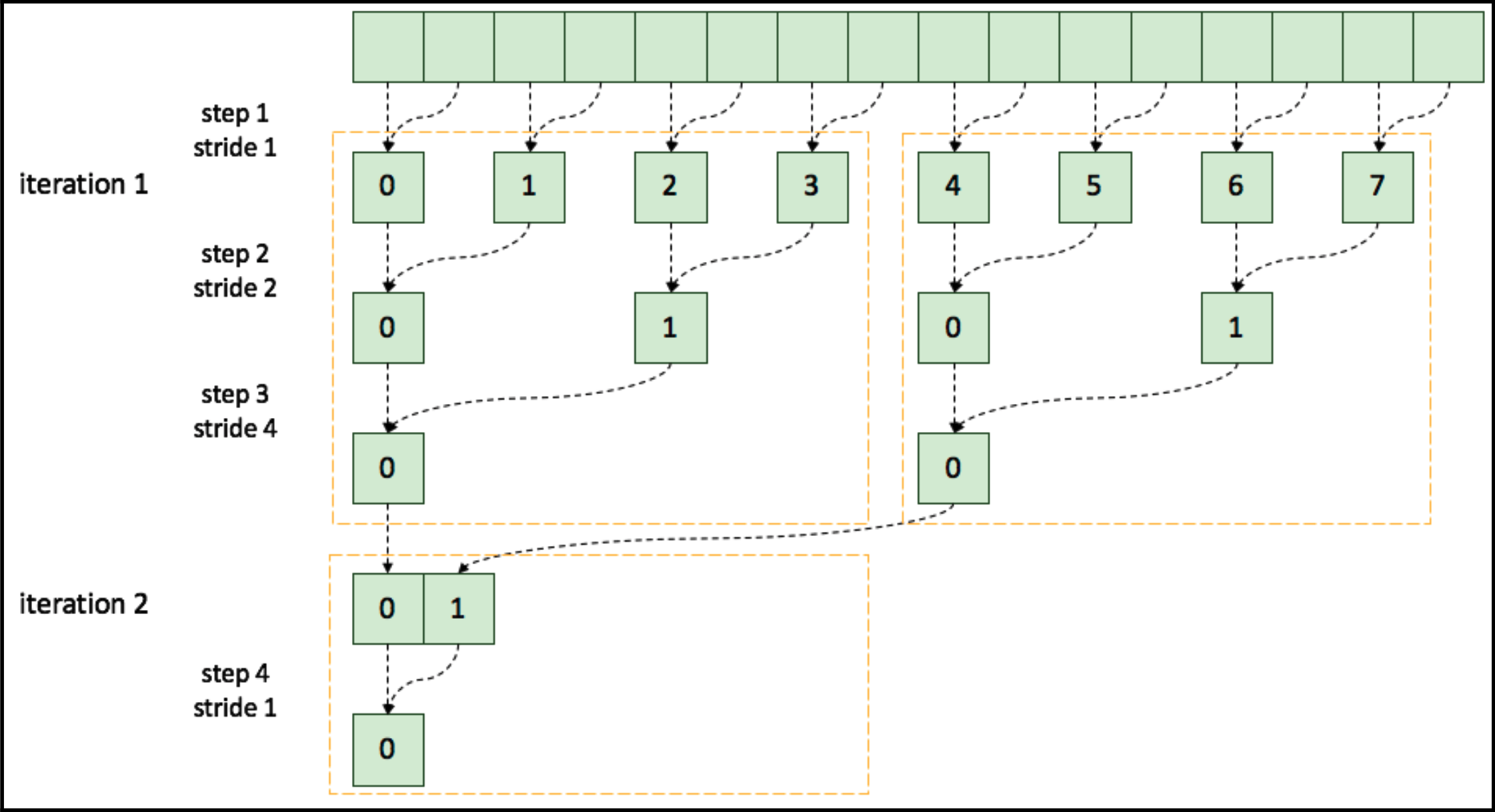
交织寻址可以实现如下:
__global__ void interleaved_reduction_kernel(float* g_out, float* g_in, unsigned int size)
{
unsigned int idx_x = blockIdx.x * blockDim.x + threadIdx.x;
extern __shared__ float s_data[];
s_data[threadIdx.x] = (idx_x < size) ? g_in[idx_x] : 0.f;
__syncthreads();
// 执行减少操作
// 交织寻址
for (unsigned int stride = 1; stride < blockDim.x; stride *= 2) {
int index = 2 * stride * threadIdx.x;
if (index < blockDim.x)
s_data[index] += s_data[index + stride];
__syncthreads();
}
// for (unsigned int stride = 1; stride < blockDim.x; stride *= 2) {
// // 线程同步规约
// if ( (idx_x % (stride * 2)) == 0 )
// s_data[threadIdx.x] += s_data[threadIdx.x + stride];
// __syncthreads();
// }
if (threadIdx.x == 0)
g_out[blockIdx.x] = s_data[0];
}
在 Tesla V100 上,测得的内核执行时间为 0.446 毫秒。这比之前的版本慢,因为在这种方法中,每个线程块没有充分利用。通过对其性能进行分析,我们可以得到更多详细信息。
现在我们将尝试另一种寻址方法,该方法旨在使每个线程块计算更多数据。
顺序寻址
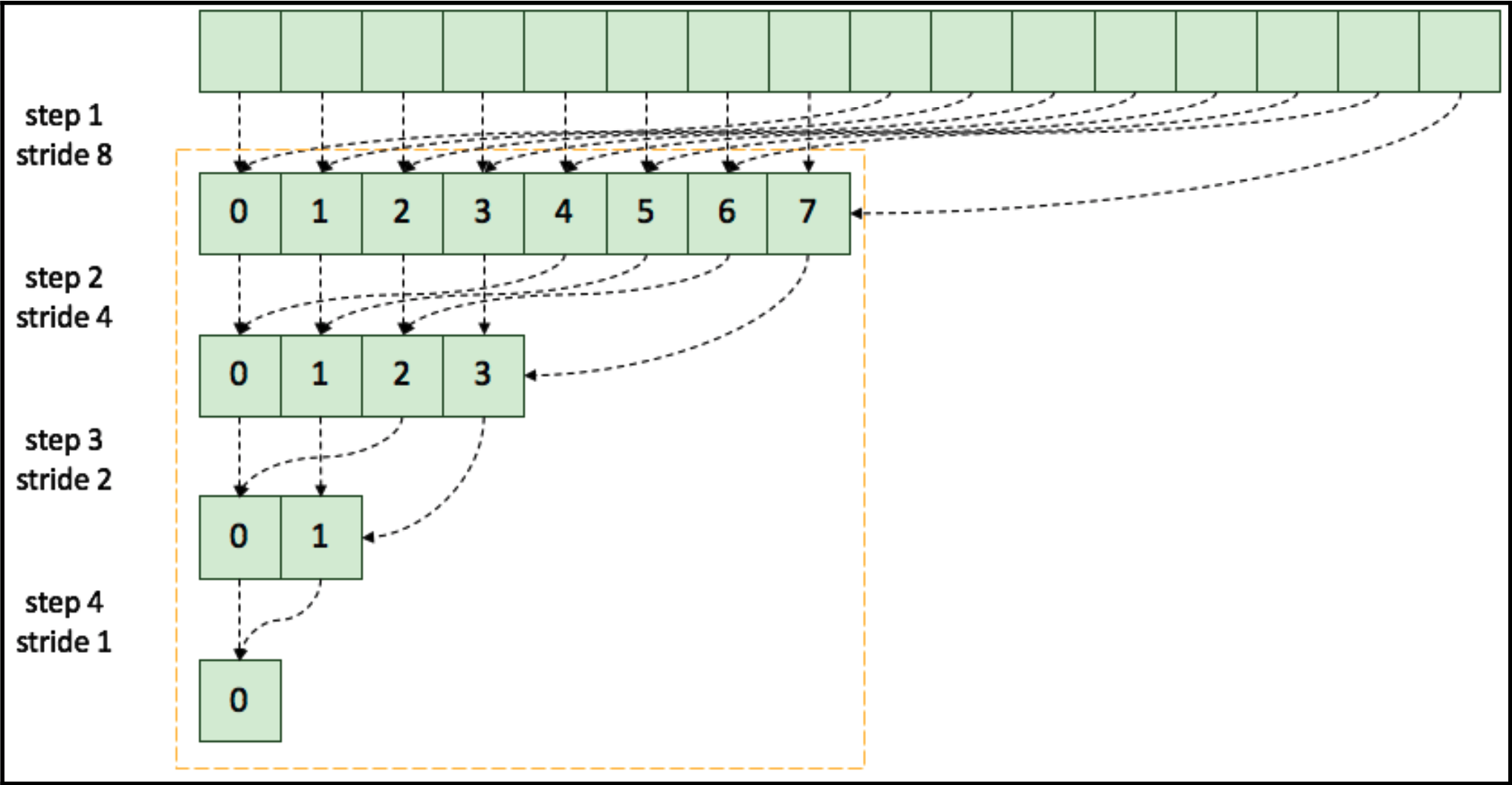
现在,让我们编写一个使用顺序寻址的内核:
__global__ void sequantial_reduction_kernel(float *g_out, float *g_in, unsigned int size)
{
unsigned int idx_x = blockIdx.x * blockDim.x + threadIdx.x;
extern __shared__ float s_data[];
s_data[threadIdx.x] = (idx_x < size) ? g_in[idx_x] : 0.f;
__syncthreads();
// 执行减少操作
// 顺序寻址
for (unsigned int stride = blockDim.x / 2; stride > 0; stride >>= 1)
{
if (threadIdx.x < stride)
s_data[threadIdx.x] += s_data[threadIdx.x + stride];
__syncthreads();
}
if (threadIdx.x == 0)
g_out[blockIdx.x] = s_data[0];
}
运行以下命令来编译上述代码:
$ nvcc -run -m64 -gencode arch=compute_70,code=sm_70 -
I/usr/local/cuda/samples/common/inc -o reduction ./reduction.cpp
./reduction_kernel_sequential.cu
在 Tesla V100 GPU 上,测得的执行时间为 0.378 毫秒,略快于前一策略(0.399 毫秒)。
性能建模和限制器平衡
在性能限制器分析之后,尽管限制器分析显示每种资源都得到了充分利用,但是我们当前的性能降低问题还是受限于内存带宽导致的计算延迟。下面我们将讨论为什么会出现这个问题,以及我们如何通过遵循 Roofline 性能模型来解决这个问题。
Roofline 模型
Roofline 模型是一种直观的可视化性能分析模型,用于在并行处理单元上提供给定计算内核的估计性能。基于该模型,并行编程中的开发人员可以确定算法应该被限制的边界,并确定应该优化的部分。
以下图形展示了 Roofline 模型的示例:
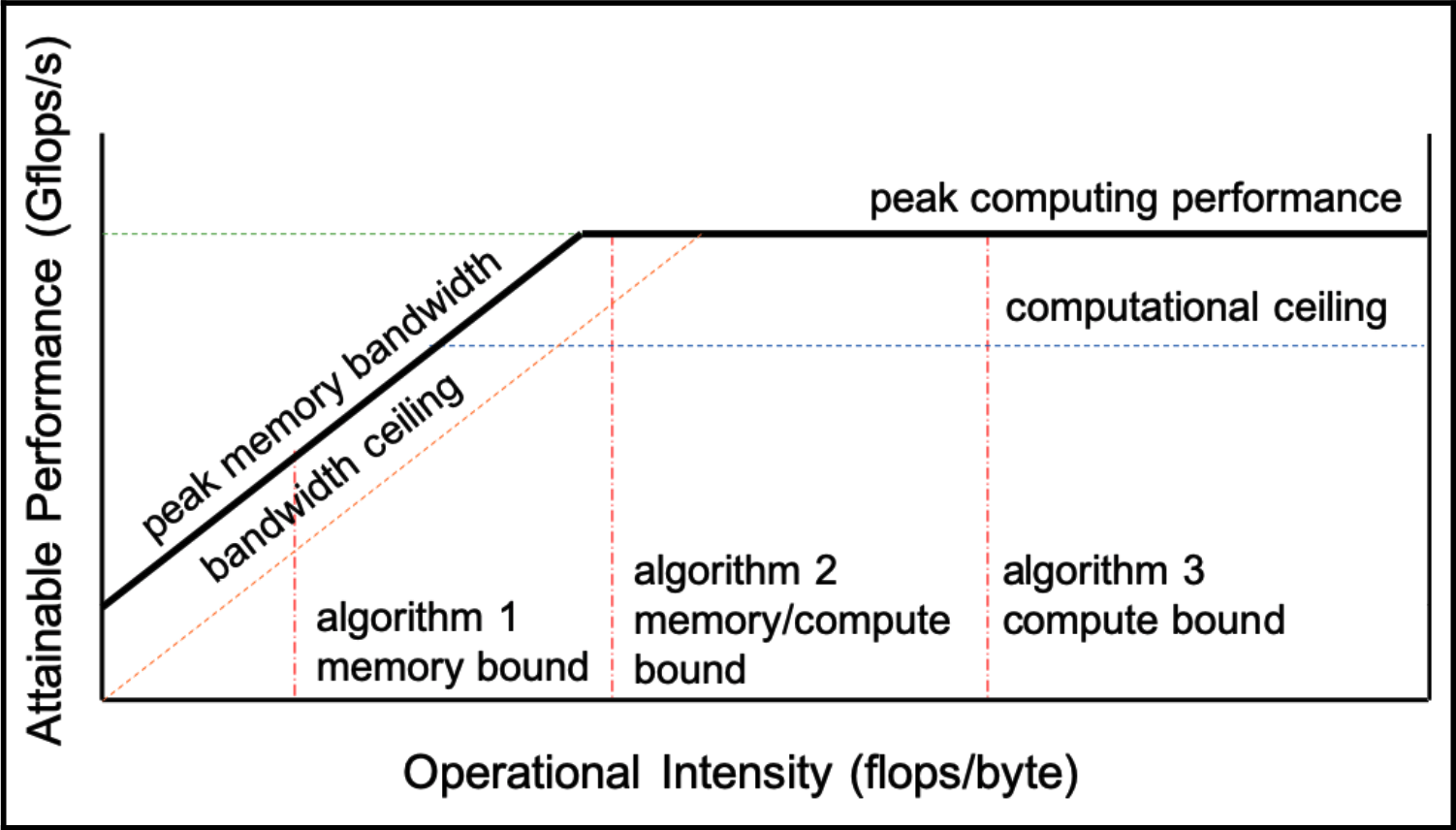
倾斜的部分表示内存受限,而平坦的部分表示算术受限。每个并行算法和实现都有自己的 Roofline 模型,因为它们具有不同的计算能力和内存带宽。通过这个模型,可以根据算法的操作强度(flops/bytes)对其进行放置。如果实现不符合该模型的预期性能,我们可以确定该版本的代码受延迟的限制。
考虑到我们并行规约的复杂性,它必须受限于内存带宽。换句话说,它的操作强度较低,因此我们的策略应该尽可能最大化内存带宽。
因此,我们需要确认我们的规约函数是如何性能带宽的。下图显示了全局内存的带宽使用情况:

正如我们从这个图表中看到的那样,我们没有充分利用全部的内存带宽。在 Tesla V100 GPU 上,程序的总带宽为 343.376 GB/s,由于这款 GPU 使用的是 900 GB/s 带宽的 HBM2 内存,因此大约只使用了带宽的三分之一。下面就让我们来看看如何增加程序的内存带宽占用。
通过网�格跨度循环最大化内存带宽
接下来我们将探讨如何通过一种简单的方法最大化内存带宽。这种方法涉及到使用 CUDA 线程来累积输入数据并启动归约操作。以前,我们的归约实现是以输入数据的大小为起点。但现在,我们将使用一组 CUDA 线程迭代访问输入数据,而这个组的大小将成为我们核函数的网格大小。这种迭代方式被称为网格跨度循环。这种技术以有效控制多个 CUDA 核心。
下面的代码展示了更新后的归约核函数:
__global__ void reduction_kernel(float *g_out, float *g_in, unsigned int size) {
unsigned int idx_x = blockIdx.x * blockDim.x + threadIdx.x;
extern __shared__ float s_data[];
float input = 0.f;
// 使用网格跨度循环累积输入数据并保存到共享内存
for (int i = idx_x; i < size; i += blockDim.x * gridDim.x)
input += g_in[i];
s_data[threadIdx.x] = input;
__syncthreads();
// 执行归约操作
for (unsigned int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
if (threadIdx.x < stride)
s_data[threadIdx.x] += s_data[threadIdx.x + stride];
__syncthreads();
}
if (threadIdx.x == 0)
g_out[blockIdx.x] = s_data[0];
}
现在,我们需要确定核函数的网格大小。为了使我们的 GPU 代码在不同的 GPU 目标上运行,我们必须在运行时确定它们的大小。此外,我们需要充分利用 GPU 中的所有多处理器。CUDA C 提供了相关的函数来实现这一目标。我们可以使用 cudaOccupancyMaxActiveBlocksPerMultiprocessor() 函数来获取多处理器上的最大活动块数,并使用 cudaDeviceGetAttribute() 函数来获取目标 GPU 上的多处理器数量。��下面的代码展示了如何使用这些函数并调用核函数:
int reduction(float *g_outPtr, float *g_inPtr, int size, int n_threads) {
int num_sms;
int num_blocks_per_sm;
cudaDeviceGetAttribute(&num_sms, cudaDevAttrMultiProcessorCount, 0);
cudaOccupancyMaxActiveBlocksPerMultiprocessor(&num_blocks_per_sm, reduction_kernel, n_threads, n_threads * sizeof(float));
int n_blocks = min(num_blocks_per_sm * num_sms, (size + n_threads - 1) / n_threads);
reduction_kernel<<<n_blocks, n_threads, n_threads * sizeof(float), 0>>>(g_outPtr, g_inPtr, size);
reduction_kernel<<<1, n_threads, n_threads * sizeof(float), 0>>>(g_outPtr, g_inPtr, n_blocks);
return 1;
}
这个函数还有一个额外的修改,为了避免过多的计算开销,它额外启动了一次带有单个块的 reduction_kernel() 函数。
最终,通过这些优化,更新后的归约性能在 Tesla V100 上达到了 0.278 毫秒,比之前的方法快了约 100 毫秒。
平衡输入/输出吞吐量
从分析结果中可以看出,本地变量“input”存在大量的加载/存储请求。这种大规模 I/O 对线程块的调度产生了操作依赖性的影响。在当前的数据累积过程中,最糟糕的是它对设备内存存在依赖性。因此,我们将使用额外的寄存器来发出更多的加载指令以减轻这种依赖性。以下的代码展示了我们如何实现这一点:
// 定义一个常数NUM_LOAD,表示每个线程块中处理的数据元素数量
#define NUM_LOAD 4
// CUDA核函数,用于执行归约操作
__global__ void reduction_kernel(float *g_out, float *g_in, unsigned int size)
{
// 计算每个线程的全局唯一索引
unsigned int idx_x = blockIdx.x * blockDim.x + threadIdx.x;
// 声明一个共享内存数组s_data,用于存储临时数据
extern __shared__ float s_data[];
// 声明一个数组input,用于暂存加载的数据
float input[NUM_LOAD] = {0.f};
// 使用网格步进循环累积输入数据并保存到共享内存
for (int i = idx_x; i < size; i += blockDim.x * gridDim.x * NUM_LOAD)
{
for (int step = 0; step < NUM_LOAD; step++)
{
// 加载数据并累积到input数组
input[step] += (i + step * blockDim.x * gridDim.x < size) ? g_in[i + step * blockDim.x * gridDim.x] : 0.f;
}
}
// 对input数组进行归约操作,将结果存储在input[0]中
for (int i = 1; i < NUM_LOAD; i++)
{
input[0] += input[i];
}
// 将input[0]存储到共享内存s_data中
s_data[threadIdx.x] = input[0];
// 等待所有线程完成对s_data的写入操作
__syncthreads();
// 执行归约操作,将结果递减到s_data[0]
for (unsigned int stride = blockDim.x / 2; stride > 0; stride >>= 1)
{
if (threadIdx.x < stride)
{
s_data[threadIdx.x] += s_data[threadIdx.x + stride];
}
// 等待所有线程完成对s_data的更新操作
__syncthreads();
}
// 当线程块中的第一个线程(threadIdx.x == 0)完成归约后,将结果写入全局内存
if (threadIdx.x == 0)
{
g_out[blockIdx.x] = s_data[0];
}
}
这段代码使用了三个额外的寄存器来收集全局内存数据。变量“NUM_LOAD”的值可能会因 GPU 的不同而有所变化,因为它受到 GPU 的内存带宽和 CUDA 核心数量的影响。
当使用 Tesla V100 卡运行以下命令时,获得的性能为 0.264 毫秒:
$ nvcc -run -m64 -gencode arch=compute_70,code=sm_70 -I/usr/local/cuda/samples/common/inc -o reduction ./reduction.cpp ./reduction_kernel_opt.cu