Fast End2End Trainable Guided Filter
论文名称:Fast End-to-End Trainable Guided Filter
作者:Huikai Wu, Shuai Zheng, Junge Zhang, Kaiqi Huang
摘要和介绍
- 全卷积神经网络(FCN)的出现大大推进了密集预测任务的进程,但是其处理联合上采样(joint upsampling,大概就是使用多个输入进行上采样)的能力有限;
- 为了解决这个问题,提出了一个 Deep Guided Filter 模块,能够利用低分辨率的输入和高分辨率的 Guided Map,生成高分辨率的输出,该模块具有以下优点:
- 可集成:可以被集成到 FCN 中,实现端到端的训练;
- 通用:可以适应从图像处理到计算机视觉的各种任务;
- 快速:可减小整个网络的参数量和计算量,某些任务相较于 SOTA 可以快 10-100 倍;
- 准确:快速的同时性能不下降甚至有所�提升;
- 可微分:相较于 Guided Filer(何恺明大佬的工作)实现了可微分(其实原版也能微分,但是论文中没有反向传播的步骤,只是用来做后处理,可微不是关键,关键是是否有能训练的参数),能端到端训练;
- 可监督:直接受高分辨率 ground truth 的监督。
相关工作
Joint Upsampling
介绍了之前的相关工作,但是没说什么是 Joint Upsampling。
许多方法都是基于 edge-preserving local filer(保留边缘的局部滤波器)的,也有一些方法是人为的设计一些函数来包含一些或者所有的像素,他们的缺点主要是
- 依赖于手工设计的目标函数;
- 耗时。
Deep Learning based Image Filter
目前也有很多工作使用深度学习的方法来近似和改善 Filter,但是 DGF 具有跟良好的通用性和最优的质量的速度。
Method
Guided Filter
Guided Filter 是一种边缘保持的滤波器(edge-perserving filter),此外还有双边滤波和最小二乘滤波等,引导滤波的时间复杂度较低。
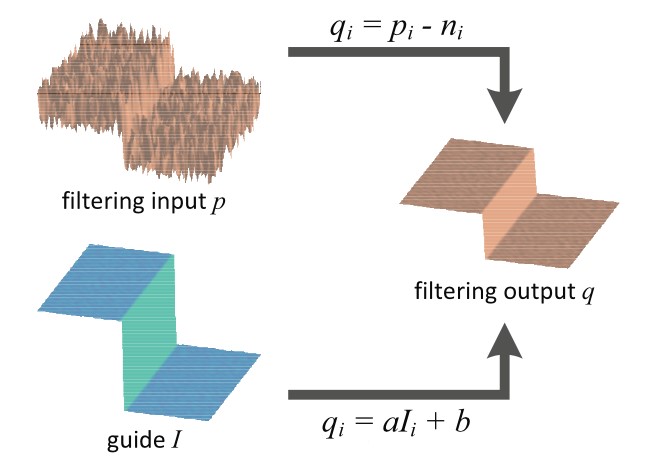
导向滤波的一个核心假设是输入图像与引导图像在滤波窗口中存在局部的线性关系:
这里的 k 表示窗口中间的像素,两边求梯度:
这大概就是为什么能保留梯度的原因了;
同时我们认为输入图像 p 窗口中非边缘的部分,是由平坦的区域和噪声组成的:
我们的目标就是最小化噪声 n,使得 p 和 q 更为接近;
接下来解出 就行了,具体使用了岭回归,但是解出的仍然是局部窗口中的值,导向滤波认为,某函数上一点与其邻近部分的点成线性关系,一个复杂的函数就可以用很多局部的线性函数来表示,当需要求该函数上某一点的值时,只需计算所有包含该点的线性函数的值并做平均即可,实际上就是计算所有包含某个像素点的窗口的 的平均值,由此可得:

一些值得注意的点:
- 第三步中,如果导向图(导向图一般以边缘为主)方差较小,也就是处于平坦区域,则 I 和 P 的协方差约等于 0, 也就约等于 0,所以 约等于 1,也就是 ,这意味着在平滑区域相当于对 p 进行了均值滤波;
- 如果方差大,也就是包含边缘, 约等于 1, 约等于 0,保证边缘的梯度基本不变。
Deep Guided Filter
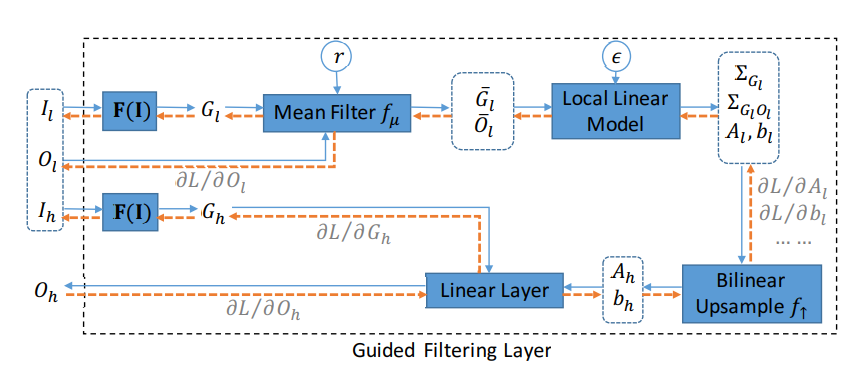
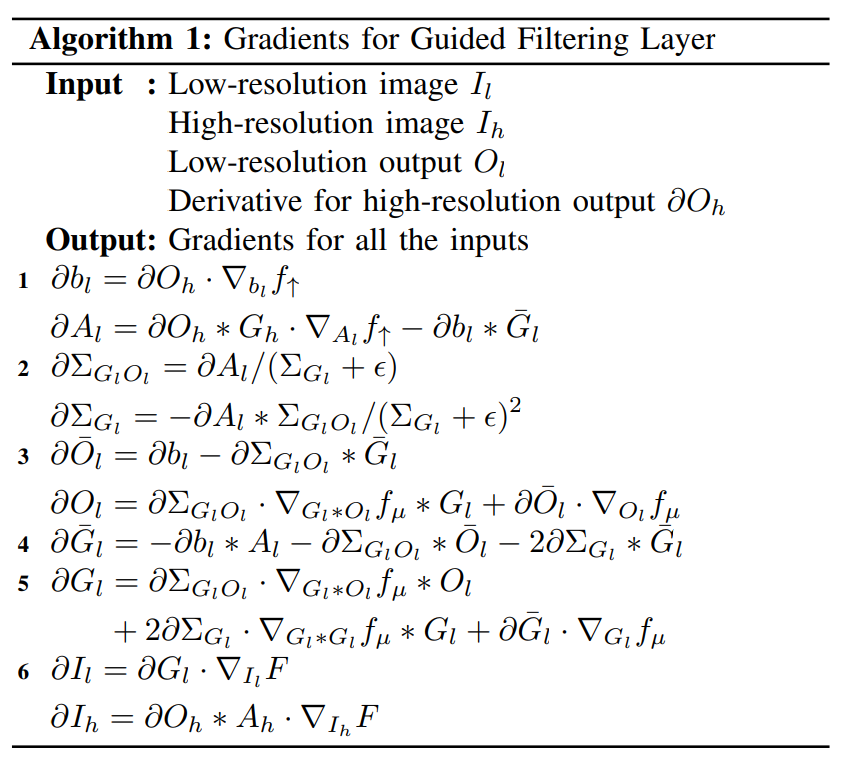
初看这个图很吓人,其展示了 Guided Filtering Layer 正向和反向传播的计算图,看不懂直接看 Convolution 的版本
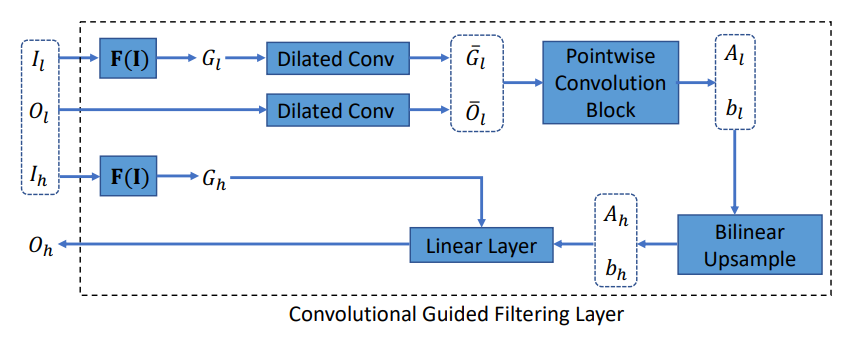
其中 的作用就是为了适应不同的任务而设计的。
使用方法
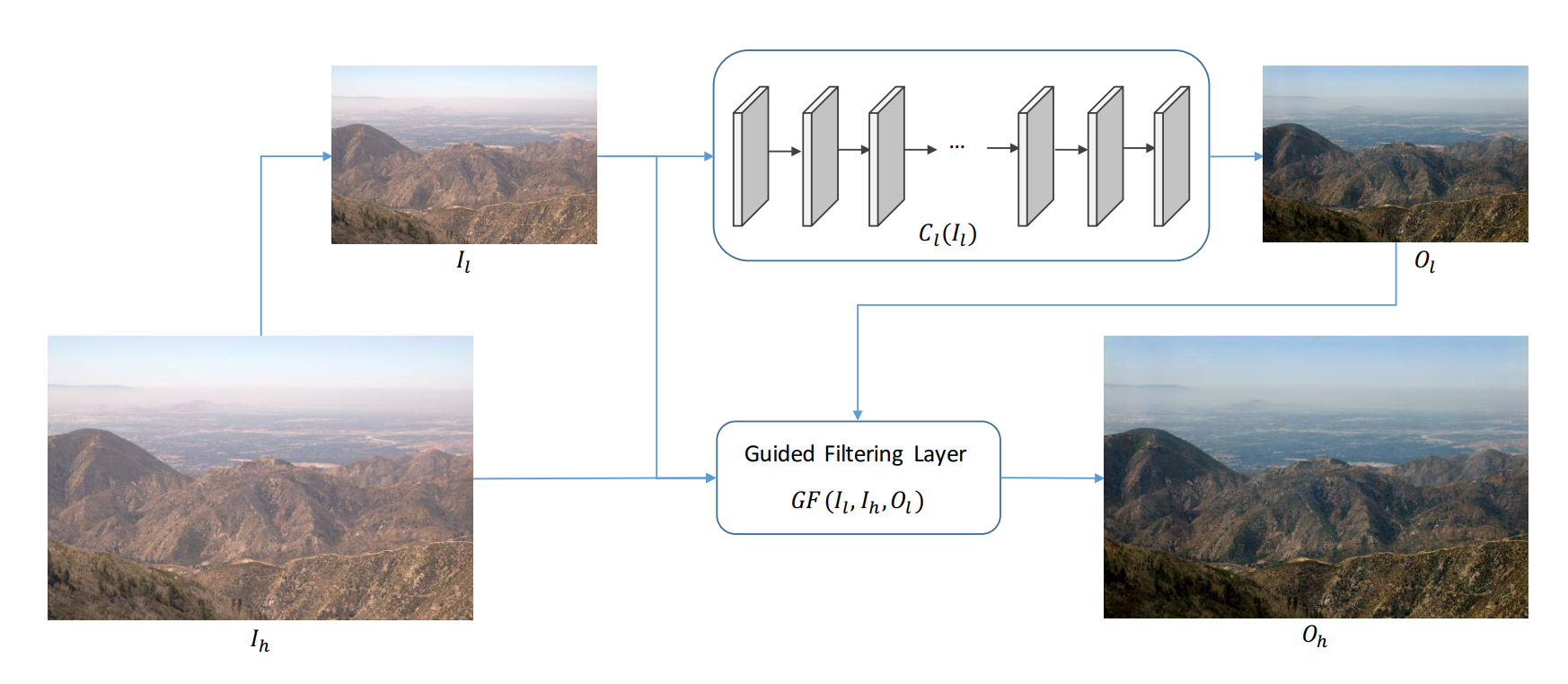
表示任意的 FCN,对于一个输入的高分辨率图像 ,首先对其进行下采样得到低分辨率的输入 ,再输入进 FCN 中得到低分辨率的输出 ,最后通过 Guided Filtering Layer 得到恢复好的高分辨率的输出,这也是 DGF 能够提高网络速度的原因。