You Only Look Once-Unified, Real-Time Object Detection
论文名称:You Only Look Once: Unified, Real-Time Object Detection
作者:Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
摘要
- 提出了一种目标检测的新方式——YOLO,不同于之前的工作利用分类器来进行检测,作者将目标检测化为空间分离的边界框(bounding box)和相关类概率的回归问题,使得 YOLO 能够进行端到端的预测;
- base YOLO 拥有 45 的帧率,而较小版本 Fast YOLO 拥有 155 的帧率,并且仍然实现了其他实时检测器两倍的 mAP;
YOLO
YOLO 将输入图像划分为一个 的网格(grid),如果某个物体的中心落入某个网格单元(grid cell),则该网格负责检测该对象;每个单元会预测 B 个 Bounding Box(这是为了同时对大小的物体进行预测)及其置信度,置信度反映了物体被包含的概率以及Box 预测的准确性,其定义如下:
Pr(object) 的值为 0 或 1,当框中没有物体时,则置信度为 0。
每一个 Bounding Box 将会预测 5 个值:x、y、w、h 和置信度。 表示 box 对于网格单元的中心的偏移,h、w 表示 box 相对于整个图片的高度和宽度(会归一化)。
每个网格单元还预测 C 个类别概率,表示其在包含 object 的条件下属于某个类别的概率(也就是条件概率)��,在测试时,将类别概率和置信度相乘
来得到每一个 Bounding Box 对特定类别的置信度,对于一个物体的多个 Box,会使用非极大值抑制(NMS)来去除重复的框。
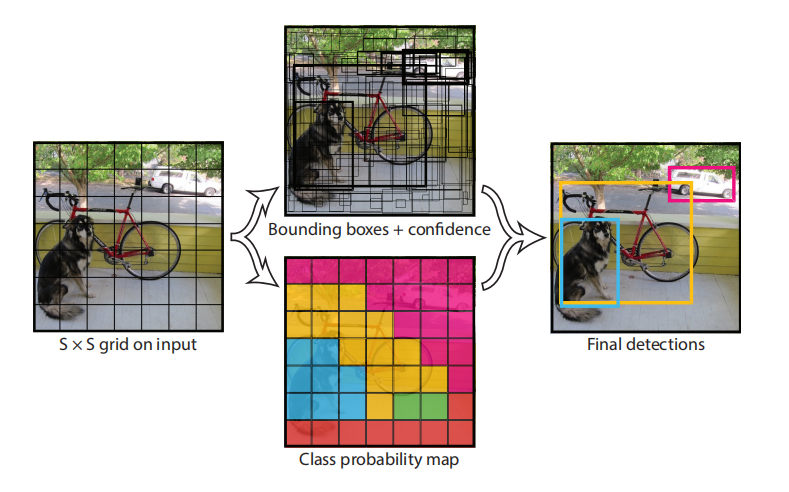
总结一下,每个 grid 会预测 B 个 Bounding Box 和 C 个条件类别概率,其中每个 Bounding Box 将会预测 x、y、w、h 和置信度 c 这 5 个值,YOLO 的输出是一个 的张量,可以看到,目标检测问题从分类问题变为了回归问题。
网络设计
使用卷积 + 全连接的结构进行特征提取和预测输出概率及坐标。
受到 GoogLeNet 的启发,使用 24 个卷积层和两个全连接层,但是不使用其初始模块,而是简单将 和 的卷积层应用,其中,结构如下:

训练

训练时仅仅会选择与标签 IOU 最大的一个框,也就是说每个 grid 仅仅能预测一个对象和一种类别,上图的 Class Probability map 表示每一个 grid 所预测的最高的条件概率 。
在实际训练过程中,IOU 会与其类别概率相乘得到置信度分数,
预测
输出:对于一张输入的图片,会得到一个 的张量,代表 个 grid cell 预测的结果;
置信度分数:对于某一个 grid cell,会将每个类别的条件概率与 B 个框的置信度相乘得到置信度分数,来表示 Bounding Box 包含某类物体的概率;
低置信度过滤:首先将较低置信度分数全部置零,表示不存在这些目标,这一步是为了去除“错误分类”的坐标
非极大值抑制:过滤掉低置信度的框之后往往还存在很多重复的 Box,这时使用 NMS(非极大值抑制)来去除;
对于某一个类别,将其置信度分数降序排序,所有的非 0 的 Box 都与置信度分数最大的一个 Box 计算 IOU,如果大于某个阈值,则认为这两个框重复,将置信度分数较小的那个置零;
然后再将所有非 0 的 Box 与分数第二大的 Box 计算 IOU,直到循环到最后一个非 0 的 Box,这是为了将这一类的重复的框去掉。
输出:最终输出会在剩下非 0 的 grid cell 中选择一个置信度分数最高的框;反过来说那些被舍弃的框都是置信度分数被置 0,或者是其 gird cell 中包含置信度分数更高的代表其他类别的框。
损失函数
损失函数定义为:
看起来似乎很长,其实很简单。
这里的 表示某个 grid cell 中存在真实物体的中心,这时 ; 的值分别是 5 和 0.5。
第一行表示坐标误差,其使用平方和误差(sum-squared error)计算每一个 Bounding Box 预测的坐标;
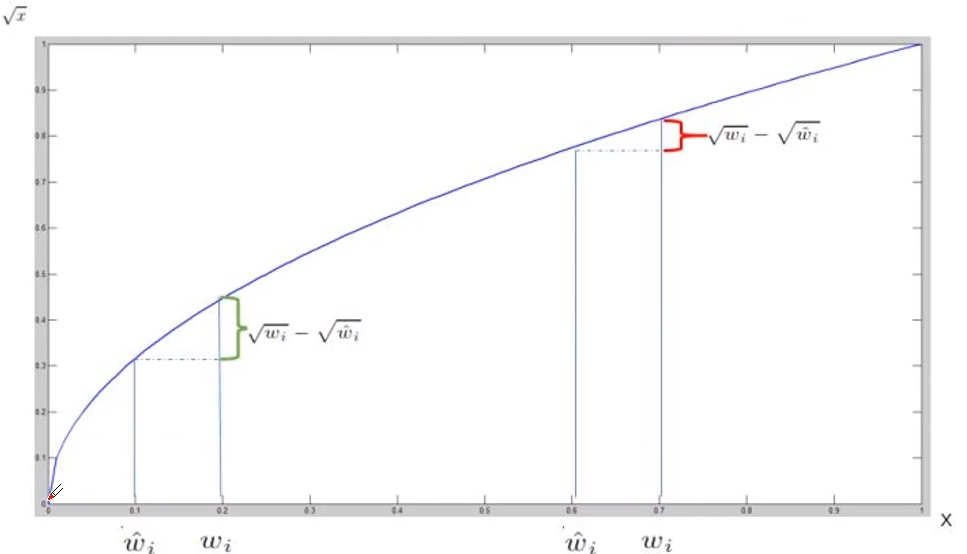
第二行表示宽高误差,这里对宽高使用了平方根是因为对于大的 Box 来说其误差影响是小于小的 Box,这里可以查阅 Boundary IOU 来进行理解,我们需要对较小 Box 拥有更大的惩罚,因此使用平方根来缓解这个问题,其函数斜率递减,对于较小的尺度的误差拥有更大的值;
第三行和第四行表示置信度误差,两者分别表示 grid 中存在真实物体中心和不存在物体中心的情况,并且这里的 ;
第五行表示分类误差。
也就是说,只有当物体的中心落在了 cell 中,才会计算所有损失,否则只计算置信度损失。
局限性
YOLO 对中每个 cell 只能预测两个 Box,当某些成群的小对象出现时,如成群的鸟等,这时是无法预测的。
另外,损失函数对于不同大小的 Box 的处理方式是相同的,然而对于较大的 Box,其影响相较于较小的 Box 要小得多,可见,损失函数对于较小的 Box 惩罚不足,因此 YOLO 的主要错误来源的定位误差。