2020年代的卷积神经网络
摘要
视觉识别的革命始于 ViTs 的引入,它迅速取代了 ConvNet,一举成为最先进的图像分类模型。另一方面,虽然最原始的 ViTs 在应用于下游任务时困难重重,但是许多分层的(hierarchical )ViTs,如 Swin Transformer,重新引入了几个 ConvNet 的先验,使得 Transformer 作为通用的视觉骨干成为可能,并且在各类下游任务上性能显著。但是这种混合方法的有效性主要归功于 ViTs 的内在优势,而不是卷积的内在归纳偏置。
本文重新审视了设计空间,并测试了纯粹的 ConvNet 所能达到的极限,具体来说,将一个标准的 ResNet 逐步“现代化”,使之成为一个类似 ViTs 架构的实现,并在此过程中发现了几个有助于性能提升的关键组件。
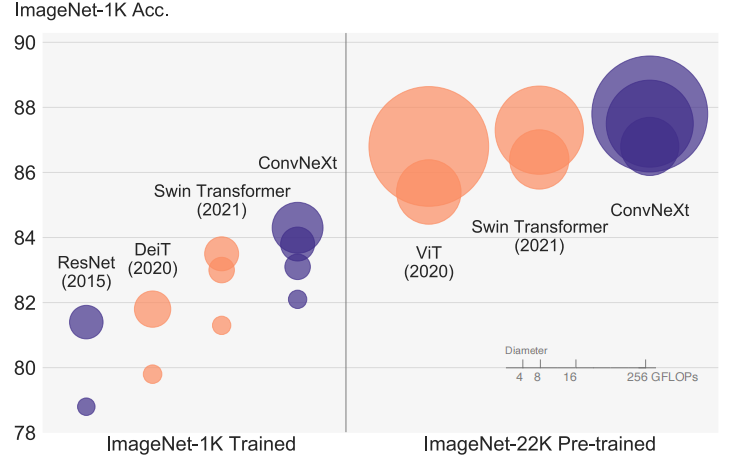
ConvNeXt 完全由标准的 ConvNet 模块构成,在准确性和可扩展性方面与 Transformer 竞争,在 ImageNet 上达到了 87.8% top-1 准确性,在 COCO 目标检测和 ADE20K 语义分割方面超过了 Swin Transformers,同时保持了标准 ConvNets 的简单性和效率。
回顾
ConvNet 的进化之路
卷积神经网络的兴起需要从 2012 年的 AlexNet 说起,它一举夺得了当年 ImageNet 分类比赛的冠军,这让人们看到了卷积神经网络在计算机视觉中的无限可能。
时间来到两年后,VGGNet 认为使用小尺寸的卷积核串联可以达到与大尺寸卷积核同样的效果,并且参数量更低,同时可以在层间添加更多的非线性以达到更好的性能。自 VGG 以后,不断堆叠的 3×3 网络便成为了主流的卷积神经网络设计范式。
同年的另一篇论文 Inceptions 夺得了 ImageNet 上的冠军,而 VGG 则屈居第二。Inceptions 探索了多分支对模型的影响,其影响同样延续至今。
2015 年,一篇举世瞩目的论文横空出世,它就是何恺明的 Deep Residual Learning for Image Recognition,文中提出了残差的结构,应用其设计的 ResNet 也是夺得了 ImageNet 的冠军,一时间名声大躁,影响深远。即使在今天,也有许多论文以 ResNet 为 Baseline 进行研究和探索,使其引用量突破了 10 万大关。
2016 年,ResNeXt 将 ResNet 与 Inceptions 结合,并且使用了分组卷积以减少参数,该设计对后续的轻量级神经网络设计起到了深远的影响。
同年,DenseNet 将层之间的连接做到了极致,充分利用了不同层的特征,并且缓解了梯度消失的问题。
2017 与 2018,MobileNet 连出两篇,进一步探索了分组卷积的威力——深度可分离卷积,以及与 ResNet 相反逆残差结构,这些设计更是影响了许多轻量级网络的设计。
2019 年的 EfficientNet 提出了复合模型扩张方法,这是一种模型缩放方法,从深度、宽度、输入图像分辨率三个维度来缩放模型,该设计在后续的神经网络设计中十分常见。
还有更多。。。
上述的各种设计确立了当今的卷积神经网络设计范式,无数网络都收其影响。但是同样的,它也一定程度上束缚了 2020 年代卷积神经网络的设计,因此,而今的 ConvNeXt 亟需一场革新。
共性
这些优秀的神经网络设��计背后的共性是什么呢?
局部计算、平移等变和特征分层。
这些优秀的设计先验也被使用到了 ViT 中,便得到了 Swin Transformer。
阶跃
Transformer
2017 年,Transformer 首次在 NLP 领域中得到应用,不久便立于统治之位。
受限于 NLP 与 CV 的不同,直到 2020 年,ViT 才被引入视觉领域,其统治之路也由此开始。
挑战
当时,ViT 的成功只限于图像分类任务,但是计算机视觉远远不止分类这一个任务。
同时,self-attention 的巨大时间复杂度限制了输入尺寸,使用高分辨率的图像似乎是一种奢望。而分割、检测等下游任务却正好需要高分辨率来获取更多的信息。
发展
ViT 的脚步并没有就此停下,它的成功就像一种必然。各种魔改的 VITs 也证明了自身的能力。
2021 年 Swin Transformer 横空出世,一举收揽各项任务的数个 sota,其论文也获得了当年的最佳论文——马尔奖。
Swin Transformer 借鉴了 ConvNets 的优秀先验,在局部窗口中计算自注意力,并且不同的窗口共享权重,同时分层的结构也成为其在下游任务上大展身手的资本。
但是 Swin 太复杂了,为了实现局部窗口�间的交互,cyclic shifting 被诟病不够优雅,sliding window 也并非原生实现。
但是卷积已经具备了这些要素!
ConvNeXt

让我们从最基础的 ResNet 开始,逐步进行“现代化”吧!
训练策略

为保证公平,ConvNets 与 ViTs 应该在同样的配置下进行训练。其性能获得了 2.6 的提升。
宏观设计
ResNet 中,各层的计算量占比为 3:4:6:3,而在 swin 中为 1:1:3:1。
另外一点便是使用 Patch Embedding,将 ReaNet 最开始 7×7 卷积核最大池化替换为 4×4stride 为 4 的卷积。

ResNeXt 化
使用深度可分离卷积,在 ViT 中,注意力的加权和操作也是在 pre-channe 的,同时增加了通道数,以弥补性能损失。

逆瓶颈结构
在 self-attention 的计算中,通道数从 C 扩张到 3C 以拆分为 KQV,后续的 MLP 中的隐藏层也有四倍的扩张。

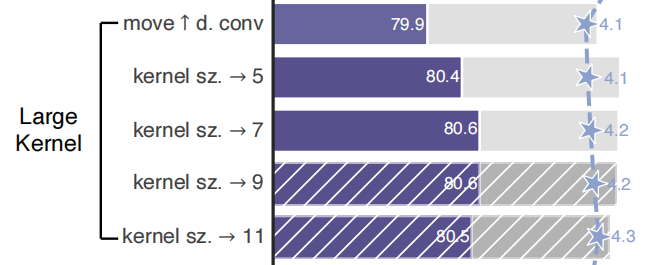
更大卷积核
将经典卷积的 3×3 尺寸扩张到与 Swin 相同的 7×7,更大尺寸则不会再涨点,这点在 RepLKNet 上也有说明,可能因为 7×7 的尺寸在 ImageNet 的分类任务上已经足够了,而在需要更大尺寸的下游任务则可以继续涨点。
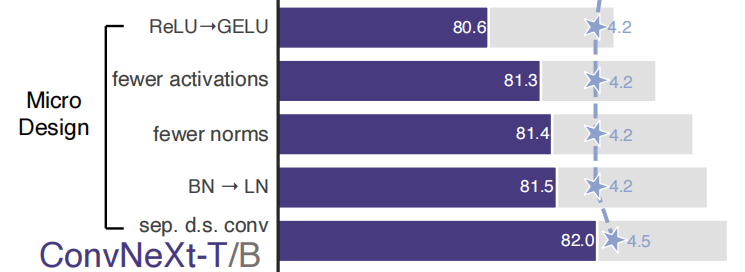
微观设计
借鉴了 Transformer 的微观设计,具体如下:
- 将 ReLU 改为 GeLU;
- 使用更少的激活函数和归一化层;
- 将 BatchNorm 改为 LayerNorm;
- 使用单独的下采样层和归一化层,每个 Block 内的分辨率不变。
结果
现代化后的 ConvNeXt 对比如下:

显而易见,ConvNeXt 结构简单且易于实现,其性能并不输于大火的 ViTs。
ConvNeXt 为后 ViT 时代的卷积网络设计提供了指导,其对 2020 年代卷积神经网络设计范式和后续卷积神经网络的影响将不可估量,或许会就此开始一场全新的 ConvNet 设计范式革新。