DFANet
论文名称:DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation
作者: Hanchao Li, Pengfei Xiong∗ Haoqiang Fan, Jian Sun
摘要和介绍
-
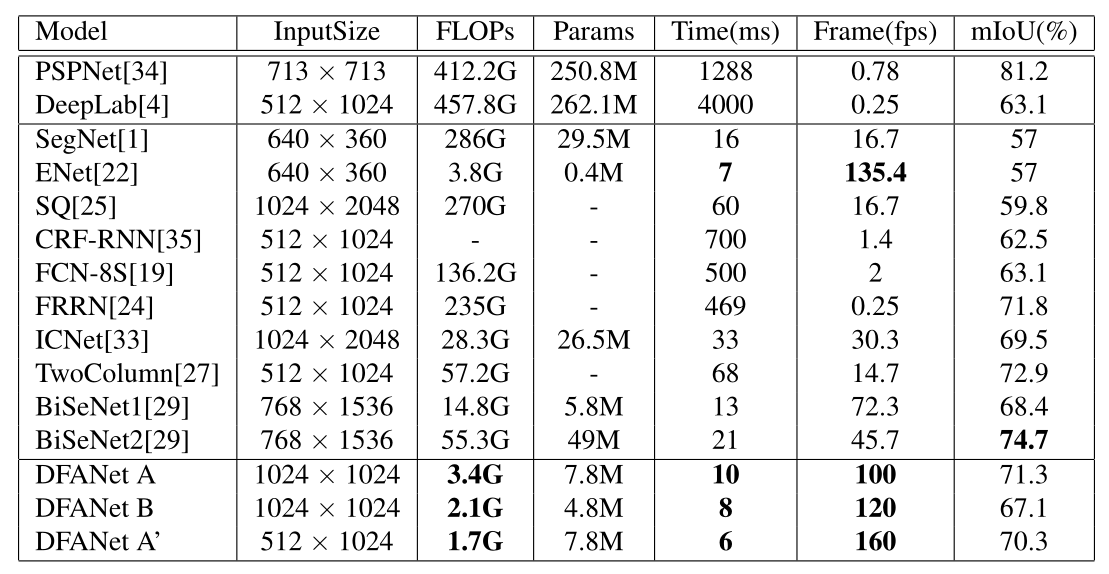
提出 DFANet,从单个轻量级主干网络开始,分别通过子网(sub-network)和子级(sub-stage)的级联来聚合显著(discriminative)特征,基于多尺度特征传播,大大降低了参数量,但仍然获得了足够的感受野,增强了模型的学习能力。相较于 sota 减小了 8 倍的 FLOPs,速度增快 2 倍;
-
在 DFANet 中,提出两种策略来实现模型中的跨级别特征聚合。第一,重用主干提取的高级特征,以弥合语义信息和结构细节之间的鸿沟。第二,结合网络体系结构处理路径中不同阶段的特征,增强特征表示能力。这些想法如下图所示 :
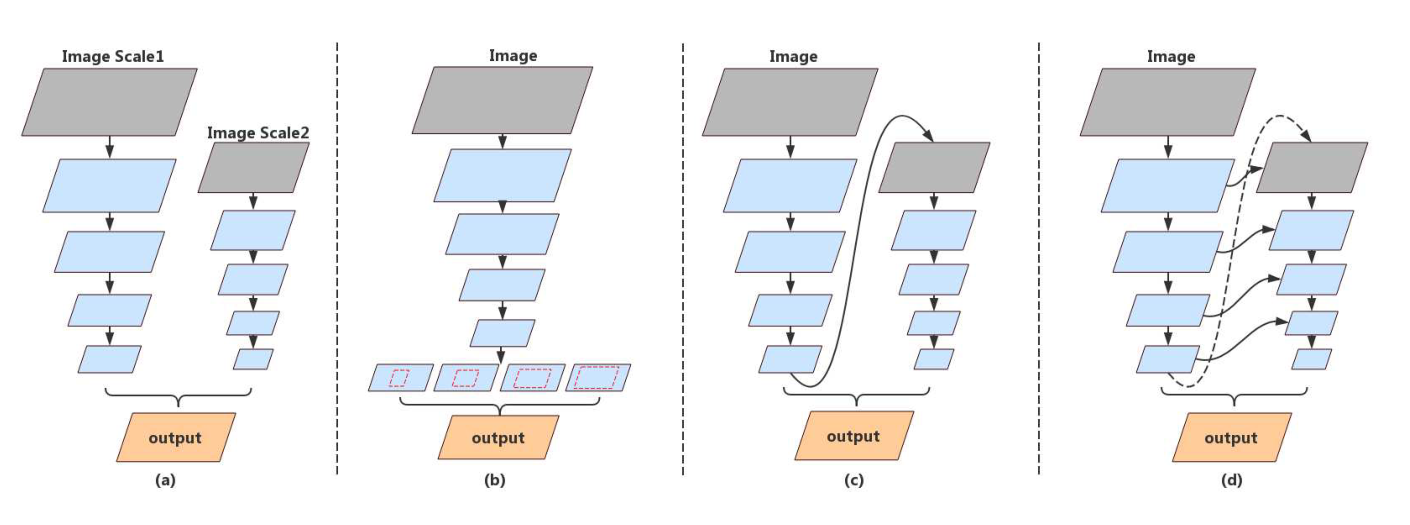 上图分别表示多分支、特征金字塔、网络级的特征重用、阶段级的特征重用。
上图分别表示多分支、特征金字塔、网络级的特征重用、阶段级的特征重用。BiSeNet 就是多分支的经典网络,但是多分支模型其缺点十分明显,它们缺乏处理并行分支的能力,并且并行分支之间缺乏通信。
语义分割中,空间金字塔池化经常被使用,但是其非常耗时。
方法
作者从实时语义分割方法的计算量开始观察和分析,这促使作者在特征提取网络的不同深度设置将细节和空间信息结合的聚合策略。
网络整体结构如图所示:
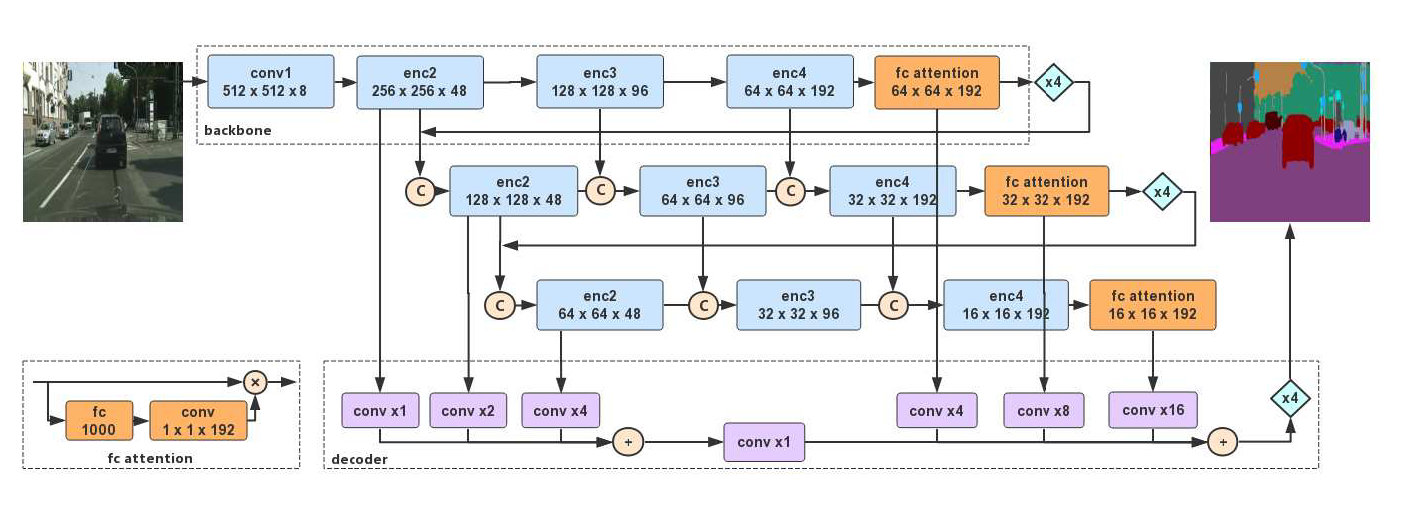
其中 c 表示 concat,xN 表示上采样操作。
网络结构图看起来很复杂,其实就是网络级的特征重用和阶段级的特征重用结合。
网络结构
DFANet 可以视为一个编码器 - 解码器结构,编码器由三个 Xception 主干组成,通过子网络聚合和子阶段聚合方法组成,对于实时推理,我们通常不太关注解码器,因此解码器被设计为一个简单高效的上采样模块,用于融合高低级特征。
Backbone:
基础的 backbone 是一个轻量级的 Xception 网络,几乎没有对其修改;
对于语义分割任务,不仅需要获取密集的特征表示,还要获取语义上下文的表达,因此,保留了 backbone 在 ImageNet 上预训练时的全连接层来增强语义信息的提取,这也是文中 fc attention 的由来。
Encoder:
编码器由三个 backbone 组成,分别使用两种聚合策略——子网络聚合和子阶段聚合,具体流程如下:
- 第一个主干网络会下采样8 倍,其输出会上采样4 倍,与 enc2 输出的特征图 concat 输入第二个主干网络;
- 第二个主干网络会下采样4 倍,其输出会上采样4 倍,与 enc2 输出的特征图 concat 输入第三个主干网络,其中每个 encn 之间都会接受来自第一个主干网络对应大小的输出作为额外输入与前一个 encn 进行 concat;
- 第三个主干网络同理 。
Decoder:
解码器没有使用太多卷积,结构如下:
- 接受每个主干的 enc2 的输出,使用一层卷积并上采样到 DFANet 输入图片的四分之一大小相加;
- 接受每个主干的最终输出,使用一层卷积并上采样到输入图像四分之一再相加;
- 将第一步的结果使用 1×1 卷积映射到相同的通道数与第二步结果相加,四倍上采样得到最终输出。
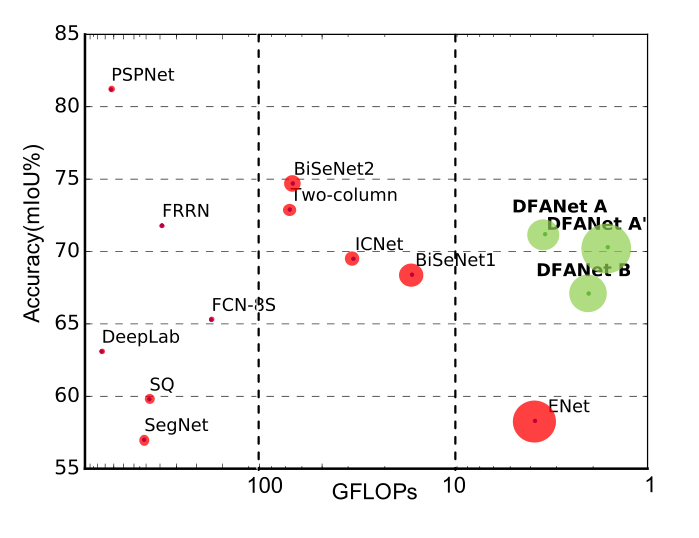
结果