Robust High-Resolution Video Matting with Temporal Guidance
论文名称:Robust High-Resolution Video Matting with Temporal Guidance
作者:Shanchuan Lin1, Linjie Yang, Imran Saleemi, Soumyadip Sengupta
摘要和介绍
- 提出了一种鲁棒、实时、高分辨率的视频 human matting 方法——RVM,实现了 SOTA 性能,在 1080Ti 上处理 4K 视频能到达 76FPS,处理 1080p 图像能达到 104FPS;
- 与大多数现存的方法不同,它们将每个输入的帧都视为独立的图像,而 RVM 能够更好的捕捉
temporal coherence(即视频中帧与帧之间的相关性),达到:- 降低“闪烁”,即前后两帧预测结果相差较大,视觉上形成闪烁效果;
- 提高鲁棒性,某一帧可能是模糊的,而网络可以通过之前的帧来进行“猜测”;
- 隐式地学习背景,摄像机或是主体对象移动时会暴露背景;
- 提出了一种新颖的训练策略,使得网络能够同时进行 Matting 和 Segmentation,这也是 RVM 鲁棒性的主要来源之一,使用 Segmentation 的原因:
- Matting 数据集多是合成的,不够真实,阻止了网络的泛化性;
- 之前有工作在分割数据上进行预训练,但是它们会在合成的分布上过拟合;
- 也有人尝试在无标签的真实图像上进行对抗性训练或半监督学习,以此来作为额外的适应步骤;
- 本文认为 human segmentation 和 human matting 任务十分相近,因此同时进行分割来调整网络,而不需要额外的适应步骤。
- 此外,有相当多的分割数据集是可用的;
- 不需要任何辅助性的输入,如 Trimap、预先拍摄好的背景(见论文 Background matting: The world is your green screen)等。
相关工作
Trimap-based matting
数学上,一张图片 可以被建模为前景 和背景 的线性组合:
然而,上式只有 是已知的,因此这是一个定义不明确的(ill-defined)问题。
为了解决这个问题,多数方法需要一个 trimap 来表示一张图片中已知的前景、背景和未知的部分。
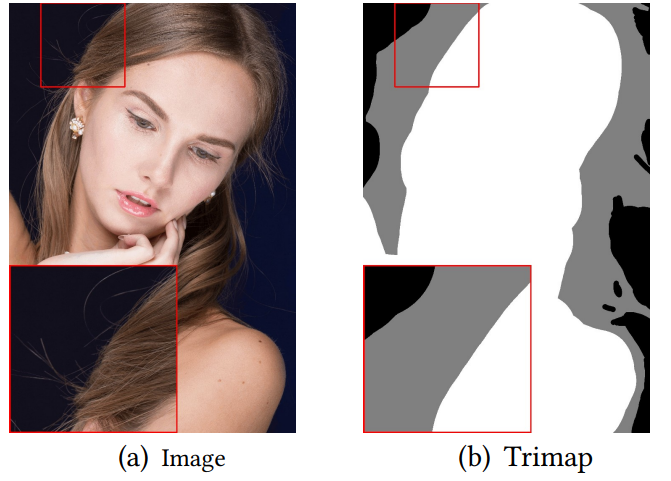
基于 trimap 的方法通常是 object agnostic,即不限定于人,它们适用于交互式照片编辑应用,用户可以选择目标对象并提供手动指导;这类方法往往精度更高。
为了拓展到视频应用中,DVM 需要第一帧的 trimap,并且会将其广播至剩下的所有帧。
Background-based matting
BGM 和 BGM-v2 提出了一种使用预先拍摄好的背景作为额外输入的方法,该方法通过获得的背景信息可以更好的预测前景,但是这种方法不能处理动态背景或是较大的摄像机移动的情况
Segmentation
Segmentation 为每一个像素都预测一个类别,并且通过不需要任何辅助性的输入,但是直接进行背景替换会造成强烈的 artifacts(伪影)。
matting 与 segmentation 的一个不同之处在于 matting 的预测结果是连续的,即预测结果是 0-1 的任意值,而 segmentation 的预测结果则是 0-nums_classes-1 的整数。
Auxiliary-free matting
全自动 matting 不需要任何辅助性的输入,一些针对所有前景的方法不够鲁棒,也有一些方法针对(human portrait)人像进行 matting。而 RVM 是针对(full human body)人的全身。
Video matting
目前来说,很少有 neural matting 的方法为视频设计(或者说是 video-native 的)。
MODnet 提出了一种后处理的技巧,通过比较相邻的帧来减少视频闪烁,但是它不能处理主体或是主体上某部分(如手)快速移动的情况,并且模型本身还是将每帧视为一个独立的图像。
BGM 使用相邻的帧作为输入,但是只能提供短期的时间关联性。
DVM 是 video-native 的,但是它利用时间信息是为了传播 trimap。
RVM 不但不需要辅助性的 trimap,并且利用时间信息来提升 matting 的质量。
Recurrent architecture
循环结构诸如 RNN、LSTM、GRU 等,被广泛应用于序列建模上,比如 NLP 中的各种任务,同时也有 ConvLSTM 和 ConvGRU 来适应 video 的任务。
High-resolution matting
Patch-based refinement(基于 patch 的优化)是一种实现高分辨的方法,比如分割任务中的 PointRend 以及 matting 中的 BGMv2;
Patch-based 是一种常见的方法,其将输入的图像分割为一个个不重叠的 patch(多数为不重叠),对每个 patch 进行处理,最终再将结果拼接回去,基于 trimap 的 matting 方法中也有很多是 patch-based。
另一种方法是使用 Guided Filter,一种后处理的方法,其将低分辨的预测结果与高分辨率的 guide map 进行联合上采样,得到高分辨率的输出结果;
Deep Guided Filter (DGF) 提出了一种端到端的、可学习的 Guided Filter 模块。
模型结构
RVM 包含一个编码器来提取单个帧的特征,一个循环的解码器来聚集时间信息,一个 Deep Guided Filter module��(DGF)来实现高分辨率的上采样。
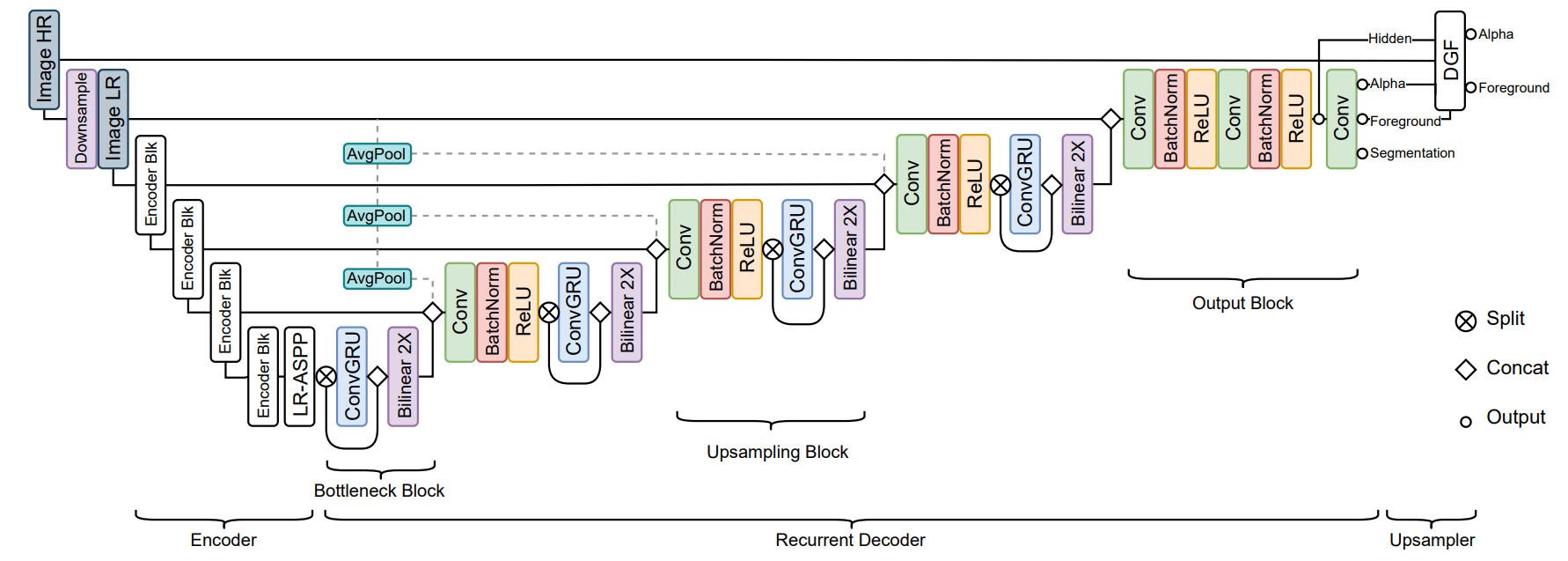
Feature-Extraction Encoder
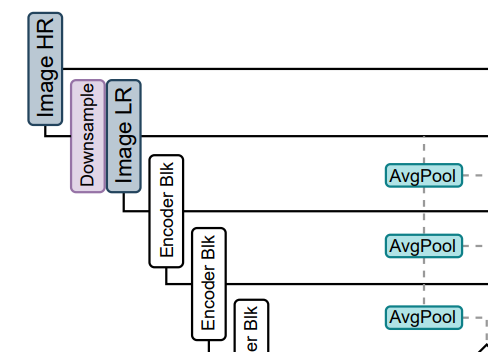
使用 MobileNet-v3 作为主干网络,在编码器最后跟一个 LR-ASPP 模块;
其中,MobileNet-v3 的最后一个 Block 使用空洞卷积而不是带步长的下采样;
编码器分别在 的尺度进行编码。
Recurrent Decoder
解码器使用 ConvGRU 组成,其实现方式只是将标准 GRU 的矩阵乘法变为了卷积操作
Bottleneck block:
在 这个尺度,为了降低和参数量,仅会对一半的通道使用 ConvGRU(We find applying ConvGRU on half of the channels by split and concatenation effective and efficient),这种方法
Upsampling block:
在 这些尺度,输入由三个部分 concat 而来——前一层的解码输出,对应的编码输出,以及通过 平均池化下采样到对应的大小的输入图像,输入图像指 ImageLR:
最后使用经典的 ConvBNReLU 来实现特征融合和调整通道数的作用。
Output block:
输出层不使用 ConvGRU,因为不起作用(we find it expansive and not impactful),直接使用两层堆叠的 ConvBNReLU,最后使用卷积映射到 5 个通道,包含 1 通道的 alpha,3 通道的 foreground,1 通道的 segmentation。
Deep Guided Filter Module
采用了 DGF 来实现高分辨率的 matting,DGF 具体看论文 Fast End-to-End Trainable Guided Filter
在高分辨图像 ImageHR 存入网络之前,对其进行了参数为 s 的下采样得到 ImageLR,经过主干网络提取特征、编码器和解码器之后,最终得到低分辨率的 alpha,和 hide feature,它们会和 ImageHR 共同输入 DGF 模块,产生高分辨的最终输出。
需要注意的是,DGF 是可选的,如果仅仅需要处理低分辨率的图像,则可以不使用 DGF。
Training
Matting Datasets
RVM 在 VideoMatte240K(VM)、Distinctions-646(D646)、Adobe Image Matting(AIM)上训练。具体细节看论文。
总之为了保证模型的鲁棒性,这些数据集的质量十分优秀。
为了提高模型对背景的理解,选取了 Deep video matting via spatio-temporal alignment and aggregation 提供的数据集,该数据集包含很多 motion,比如快速的车辆移动、树叶摇晃和摄像机移动等等,选取了 3118 组不包含人的视频,取前 100 帧数进行训练。
同时使用了 motion 和 temporal 的数据增强来更好的提升鲁棒性。
Motion augmentations include affine translation, scale, rotation, sheer, brightness, saturation, contrast, hue, noise and blur that change continuously over time
Motion 增强包含仿射变换、缩放、旋转、sheer(坐标轴倾斜)、亮度变化、饱和度变化、对比度变化、色调变化、噪声以及模糊,这些增强会随着时间变化(此处应该是指输入视频的时间,而不是训练的时间)
temporal 增强包含倒放、速度变化、随机暂停和跳帧(frame skipping)。
另外一些不连续的增强有横向翻转、灰度变化和锐化,直接对所有帧进行应用。
Segmentation Datasets
使用 YouTubeVIS、 COCO、 SPD 进行训练,采用相同的数据增强但是不包括 motion,因为 YoutubeVIS 已经包含了大量的镜头移动,并且分割本身并不需要 motion 的增强。
Procedures
训练包含四个阶段,使用 Adam 优化器,所有阶段都是用 batch sizeB=4,在 4 张 v100 上进行训练(All stages use batch size B = 4 split across 4 Nvidia V100 32G GPUs)。
Stage 1:
- 不使用 DGF 在 VM 上以低分辨率训练 15 个 epoch,设置序列长度(ConvGRU 的参数)T=15,以便让网络快速更新;
- 主干网络使用在 ImageNet 上的预训练模型,使用 lr=1e-4,其余部分的 lr=2e-4;
- 网络输入大小为 256-512。
Stage 2:
设置 T=50,学习率降为一半,其他设置不变,再训练 2 个 epoch,这是为了使网络适应长序列的输入,50 是 v100 能容纳的最大数量。
Stage 3:
- 加上 DGF,以高分辨在 VM 上再训练 1 个 epoch;
- 由于输入图像分辨率过高,T 的值必须很小,所以对高分辨的图像,设置 T=6,,对于地分辨率的图像,设置 T=40,;
- DGF 模块 lr=2e-4,其余部分为 1e-4;
Stage 4:
在 AIM 和 D646 数据集上训练 5 个 epoch,增加 decoder 的学习率至 5e-5,其他设置保持不变。
segmentation:
- segmentation 的训练是交错式的,穿插在 matting 的整个训练阶段当中,在每个奇数 iteration(迭代次数)后在 image data 上训练 segmentation,偶数 iteration 后在 video data 上训练 segmenttation;
- 对于 video data,所有设置保持和 matting 相同;
- 对于 image data,设置 T'=1,B'=T B;
Losses
具体看论文
对 帧数使用 loss,对于 alpha,使用 L1 loss 和 pyramid Laplacian loss,定义如下
同样使用了 temporal coherence loss,定义如下:
为了学习到前景,同样使用了 L1 loss 和 temporal coherence loss,定义如下:
Ablation Studies
看论文,总之就是有用。
改进
- 主干网络:使用更轻量的主干网络,比如 Shufflenetv2、RepVGG 等;
- 时序信息:设计或寻找其他能捕获时序信息的模块或结构;
- 注意力模块:添加相应的空间注意力模块或者时间注意力模块;
- 创新:使用辅助性输入来提升稳定性(非必须)。针对视频会议等进行改进,这些情况背景不会进行变化,可以仿照 BGM 输入背景图片,或者 DVM 输入三分图。
难点:
训练周期长且麻烦,各种方案可能要等较久才有结果