超越自注意力:External Attention
论文名称:Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
作者:Meng-Hao Guo, Zheng-Ning Liu, Tai-Jiang Mu, Shi-Min Hu, Senior Member
前言
自从 在 NLP 中被提出之后,许多工作尝试将其引入计算机视觉的各种任务之中,即使其被证明是一种行之有效的方法,其缺点终将会阻碍自身的进一步发展:
- 的计算复杂度呈二次增长
- 只能学习到单个样本中的长距离关系,但是无法考虑所有样本之间的关联
因此,提出了 ,仅仅通过两个可学习的单元,实现了线性的时间复杂度,并且能够考虑到所有样本之间的关联,与此同时,对整个网络起着重要的正则作用,有利于增强网络的泛化性
External Attention
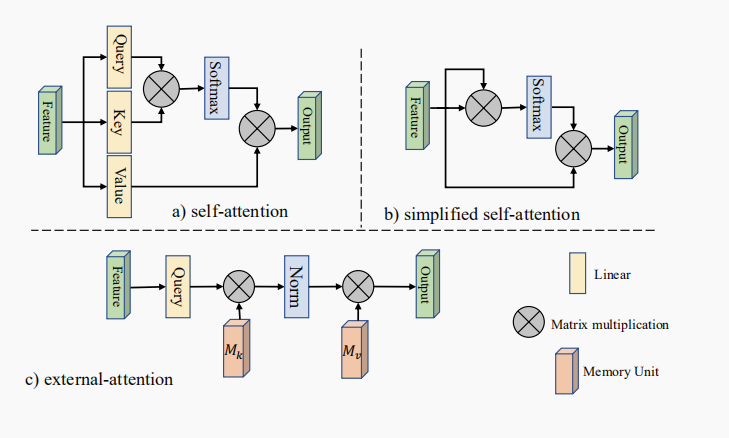
Self Attention
公式为:
具体内容移步 此
另一个简化 的公式为
其时间复杂度为
在计算机视觉的各类任务中,显然,我们不需要 NXN 的注意力图,因为像素点之间关系并不想 NLP 中词语之间的关系那么密切,因而有的工作提出了在 patch 上计算注意力。
即便能在一定程度上缓解计算消耗, 忽略了不同样本间数据的关系,在一定程度上限制了其灵活度和泛化性
External Attention
不再通过原始输入来获得 ,而使用两个独立的 ,公式如下:
在原文中,这里的 指的是第 个像素与 中第 行的相似度,我认为体现的并不明显(emmmm 我太菜了)
让我们做一个简单的推理(这里的矩阵的长宽都假设为 N):
根据矩阵的运算规则,对于 (它在第 列),那么 的第 行的所有元素都会和 相乘(注意这里是转置之后的行,在原来的 上应该是列,更加迷惑了),然而它们并不会加在一起,而是分布在一个维度 的矩阵中,并且还会有其他数据的影响,因为 所在的一行会与 的每一列乘加,
综上,我不知道相似度体现在那里
总之,ES 将时间复杂度降到了线性,其输出为:
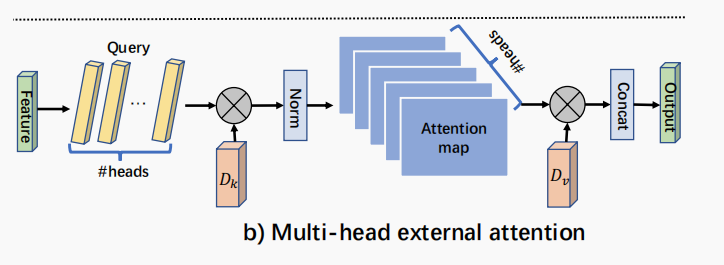
多头 External Attention 的实现如下
归一化
我们知道, 对输入的尺度大小十分敏感,因此在自注意力中使用了缩放点积来减小影响,具体移步 此
在 ES 中,使用 分别在行和列上进行归一化
这里的 实际上就是先对列进行 再对行进行
代码
class External_attention(Module):
'''
Arguments:
c (int): The input and output channel number.
'''
def __init__(self, c):
super(External_attention, self).__init__()
self.conv1 = nn.Conv2d(c, c, 1)
self.k = 64
self.linear_0 = nn.Conv1d(c, self.k, 1, bias=False)
self.linear_1 = nn.Conv1d(self.k, c, 1, bias=False)
self.linear_1.weight = self.linear_0.weight.permute(1, 0, 2) #初始化成一样是为了让 Mk 和 Mv 最开始时候是一致的,类似于 self-attention 里面的 K 和 V 都是从 X 经过线性变换来的,这种设置在训练初始阶段会稳定一些,但是貌似不会影响最终结果。
self.conv2 = nn.Sequential(
nn.Conv2d(c, c, 1, bias=False),
nn.BatchNorm(c))
self.relu = nn.ReLU()
def execute(self, x):
idn = x
x = self.conv1(x)
b, c, h, w = x.size()
n = h*w
x = x.view(b, c, h*w) # b * c * n
attn = self.linear_0(x) # b, k, n
attn = torch.softmax(attn, dim=-1) # b, k, n
attn = attn / (1e-9 + attn.sum(dim=1, keepdims=True)) # # b, k, n
x = self.linear_1(attn) # b, c, n
x = x.view(b, c, h, w)
x = self.conv2(x)
x = x + idn
x = self.relu(x)
return x
多头 EA 请自行前往仓库查找
思考
先看大佬怎么说:https://www.zhihu.com/search?type=content&q=External%20Attention
感觉 External Attention 与 Bottleneck 有一定的相似程度,首尾通过 1X1 卷积实现残差连接,不过在连接的过程中加入了 Softmax 和 l1norm 起到一定信息交换的作用
关于 :
在之前就有工作把 position-wise 的前馈层当作一个 Memory 模块
关于 :
如果你看完了输入尺度对 的影响,应该会思考,为什么要将 l1norm 添加在后面呢?
当输入特征方差过大时, 输出的会是一个接近于 的向量,此时再做 l1norm 显然不会有什么变化吧
或者说这里的 可以提取的是全局信息?
关于相似度:见 2.2