GCT:门控注意力
论文名称:Gated Channel Transformation for Visual Recognition
作者:Zongxin Yang, Linchao Zhu, Y u Wu, and Yi Yang
摘要
- GCT 模块是一个普遍适用的门控转换单元,可与网络权重一起优化。
- 不同于 SEnet 通过全连接的隐式学习,其使用可解释的变量显式地建模通道间的关系,决定是竞争或是合作。
关键词:可解释性、显式关系、门控
介绍
- 单个卷积层只对 Feature Map 中每个空间位置的临近局部上下文进行操作,这可能会导致局部歧义。通常有两种方法解决这种问题:一是增加网络的深度,如 VGG,Resnet,二是增加网络的宽度来获得更多的全局信息,如 GEnet 大量使用领域嵌入,SEnet 通过全局嵌入信息来建模通道关系。
- 然而 SEnet 中使用 fc 层会出现两个问题:
- 由于使用了 fc 层,出于节省参数的考虑,无法在所有层上使用
- fc 层的参数较为复杂,难以分析不同通道间的关联性,这实际上是一种隐式学习
- 放在某些层之后会出现问题
相关工作
门控机制
门控机制已经成功地应用于一些循环神经网络结构中。LSTM 引入��了输入门、输出门和遗忘门,用于调节模块的进出信息流。基于门控机制,一些注意力方法侧重于将计算资源集中于特征信息最丰富的部分。
归一化层
近年来,归一化层被广泛应用于深度网络中。局部响应归一化(LRN)为每个像素计算通道间一个小邻域内的统计信息;批量归一化(BN)利用批维度上的全局空间信息;层归一化(LN)沿着通道维度而不是批处理维度计算;组归一化(GN)以不同的方式将通道划分为组,并在每个组内计算均值和方差来进行归一化。
GCT
设计思路:
- 通过 p-norm 嵌入全局上下文信息
- 通过嵌入信息与可训练参数来进行通道归一化
- 通过门控权重与偏置来实现通道门控注意力机制
整体结构
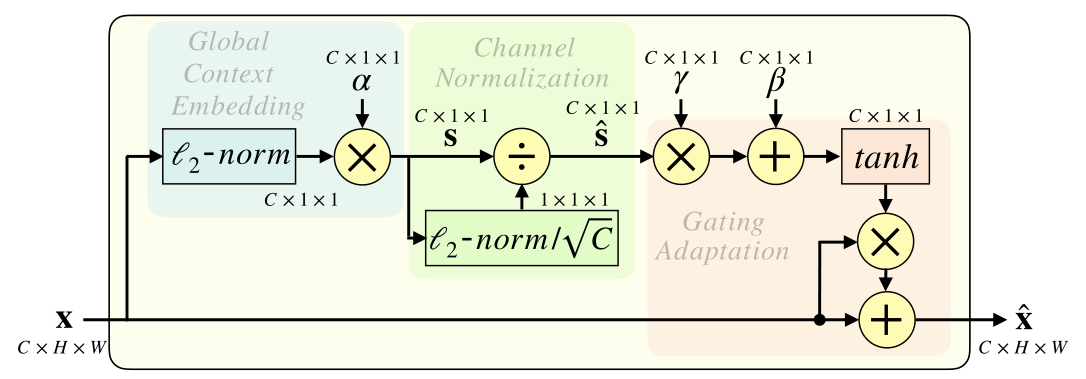
GCT 模块主要包括三个部分——全局上下文嵌入、通道归一化、和门控自适应。其中,归一化操作时无参的。
同时,为了使 GCT可学习,引入了三个权重——, 负责自适应嵌入输出。门控权重 和偏置 负责控制门的激活。
另外,GCT 的参数复杂度为 ,而 SEnet 的复杂度为 。
则 GCT 模块的激活特征为:
全局上下文嵌入
较大的感受野可以避免局部语义歧义,因此设计了一个全局上下文嵌入模块来聚合每个通道中的全局上下文信息。
GAP(全局平均池化)在某些情况下会失效,如将 SE 模块部署在 LN 层之后,因为 LN 固定了每个通道的平均数,对于任意输入,GAP 的输出都是恒定的。
这里选用了 p-norm 来进行全局上下文嵌入,2-norm 的效果最好,1-norm 的效果与其十分接近,但是注意,当 p=1 时,对于非负输入(如部署在 ReLU 之后),将等价于 GAP
其中参数 定义为 ,当 接近 0 时,该通道将不参与通道归一化
该模块定义为:
其中 为一个极小的常数避免了零点处求导问题。
通道归一化
归一化方法可以在神经元 (或通道) 之间建立竞争关系,使得其中通道响应较大的值变得相对更大,并抑制其他反馈较小的通道(该说法最早可能在 LRN论文 中提出,但是该论文并没有给出任何解释,或许当 大于 1 时会起到建立竞争关系的作用),这里使用 ��正则化来进行通道归一化。
类似于 LRN,其定义如下:
门控自适应
定义如下:
当一个通道的门控权重被积极激活时,GCT 促进该通道与其他通道竞争。当门控权重被消极激活时,GCT 鼓励该通道与其他通道合作。
此外,当门控权重和门控偏置为 0 时,允许原始特征传递到下一层:
该特性可以有效解决深层网络退化问题,ResNet 也从该思想中受益。
因此建议在 GCT 层初始化中将γ和β初始化为 0。这样,训练过程的初始步骤会更加稳定,GCT 的最终表现也会更好。
代码
class GCT(nn.Module):
def __init__(self, num_channels, epsilon=1e-5, mode='l2', after_relu=False):
super(GCT, self).__init__()
self.alpha = nn.Parameter(torch.ones(1, num_channels, 1, 1))
self.gamma = nn.Parameter(torch.zeros(1, num_channels, 1, 1))
self.beta = nn.Parameter(torch.zeros(1, num_channels, 1, 1))
self.epsilon = epsilon
self.mode = mode
self.after_relu = after_relu
def forward(self, x):
if self.mode == 'l2':
embedding = (x.pow(2).sum((2, 3), keepdim=True) +
self.epsilon).pow(0.5) * self.alpha #[B,C,1,1]
norm = self.gamma / \
(embedding.pow(2).mean(dim=1, keepdim=True) + self.epsilon).pow(0.5)
# [B,1,1,1],公式中的根号C在mean中体现
elif self.mode == 'l1':
if not self.after_relu:
_x = torch.abs(x)
else:
_x = x
embedding = _x.sum((2, 3), keepdim=True) * self.alpha
norm = self.gamma / \
(torch.abs(embedding).mean(dim=1, keepdim=True) + self.epsilon)
else:
print('Unknown mode!')
sys.exit()
gate = 1. + torch.tanh(embedding * norm + self.beta)
# 这里的1+tanh就相当于乘加操作
return x * gate
可解释性
门控权重
将门控权重在 ResNet-50 上的分布进行可视化:
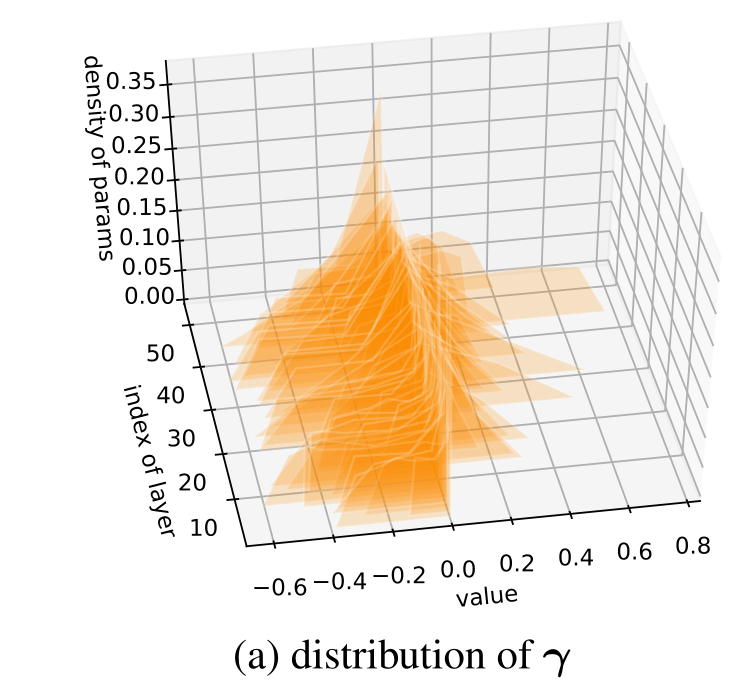
- value 代表权重的值
- index of layers 表示权重所在网络层数的维数,越大说明其位置越靠近输出
- density of params 表示参数的密度,这里做了 的处理来放缩 轴
计算门控权重在不同位置的均值和方差:
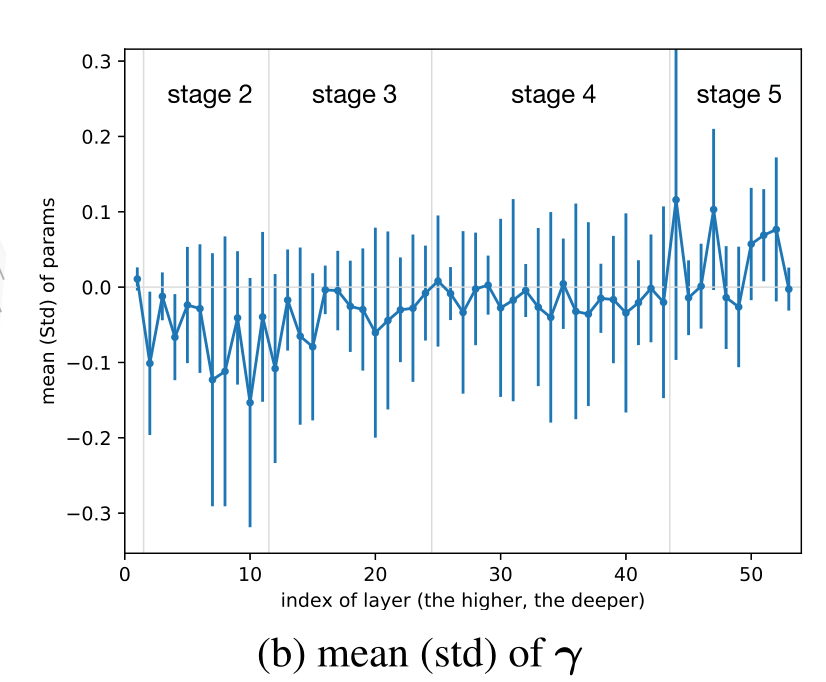
可以看到:
- 网络浅层,门控权重的均值小于 0,GCT 模块倾向于减小通道差异性,鼓励通道之间合作。
- 网络深层,门控权重的均值大于 0,GCT 模块倾向于增加通道差异性,鼓励通道之间竞争。
对于合作和竞争的解释
- 在网络浅层,主要学习低级特征,如纹理,边缘等,对于这些基础特征,我们需要通道之间进行合作,以更加广泛地提取特征。
- 在网络深层,主要学习高级特征,它们之间的差异往往很大,而且与任务有直接关系,我们需要通道之间进行竞争,来获得更有价值的特征信息。
溶解研究
本文并没有对GCT 各部分块的有效性进行探索,而是对各个部分中的 p-norm 方法以及激活函数进行对比。
文中仅仅给出了门控权重的有效性,并没有具体分析门控偏置和嵌入权重的作用。
补充
训练
将 GCT 模块添加进已有的模型时,可以先冻结网络的其他参数而只训练 GCT 模块中的参数,之后再将网络解冻一起训练。
也可以将 GCT 从一开始就加入网络之中,从头开始训练。
思考
通过 5.1 中的权重分布图可以发现,有相当大的一部分权重集中在 0 左右,是否可以说明 GCT 存在一定的冗余?
可以探索更多全局信息嵌入的方法以及归一化的方法。