开门见山,为了实现一个大小与速度都足够优秀的轻量级网络,V1 做了一件事——将 VGG 中所有��标准卷积都替换成深度可分离卷积 。
可分离卷积
可分离卷积主要有两种:空间可分离 和深度可分离
参考
空间可分离卷积
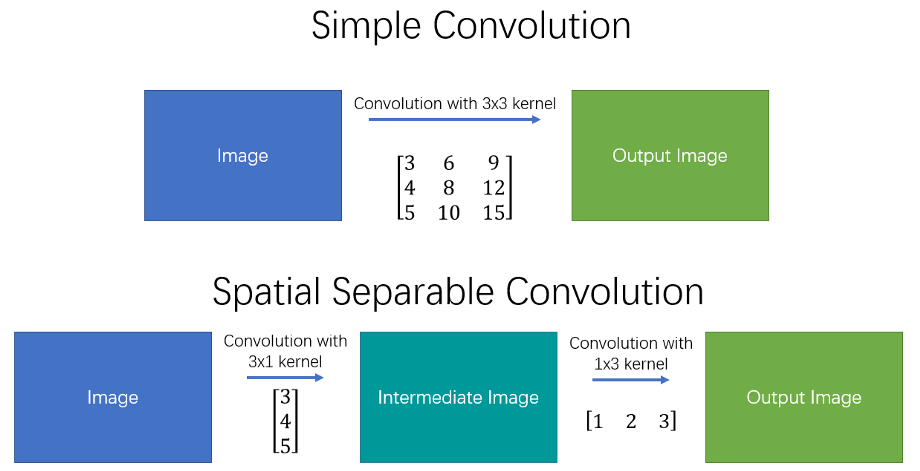
顾名思义,空间可分离卷积将标准卷积核分离成高度 和宽度 方向的两个小卷积,下式是一个非常著名的边缘检测算子——S o b e l Sobel S o b e l
[ − 1 0 1 − 2 0 2 − 1 0 1 ] = [ 1 2 1 ] × [ − 1 2 1 ] \left[\begin{array}
{c}
-1&0&1\\
-2&0&2&\\
-1&0&1\\
\end{array}\right]=
\left[\begin{array}
{c}
1\\
2\\
1\\
\end{array}\right]\times
\left[\begin{array}
{c}
-1&2&1
\end{array}\right] − 1 − 2 − 1 0 0 0 1 2 1 = 1 2 1 × [ − 1 2 1 ]
实际运算时,两个小卷积核分别与输入进行三次乘法运算,而非标准卷积的 9 次,以达到减少时间复杂度的目的,从而提高网络运行速度。
然而并非所有的卷积核都可以被分为两个更小的核,在训练时十分麻烦,这意味着网络只能选取所有小内核的一部分,因此空间可分离并没有被广泛应用于深度学习。
深度可分离卷积
对于一个特征图而言,其不止有高度和宽度,还拥有表示通道的深度
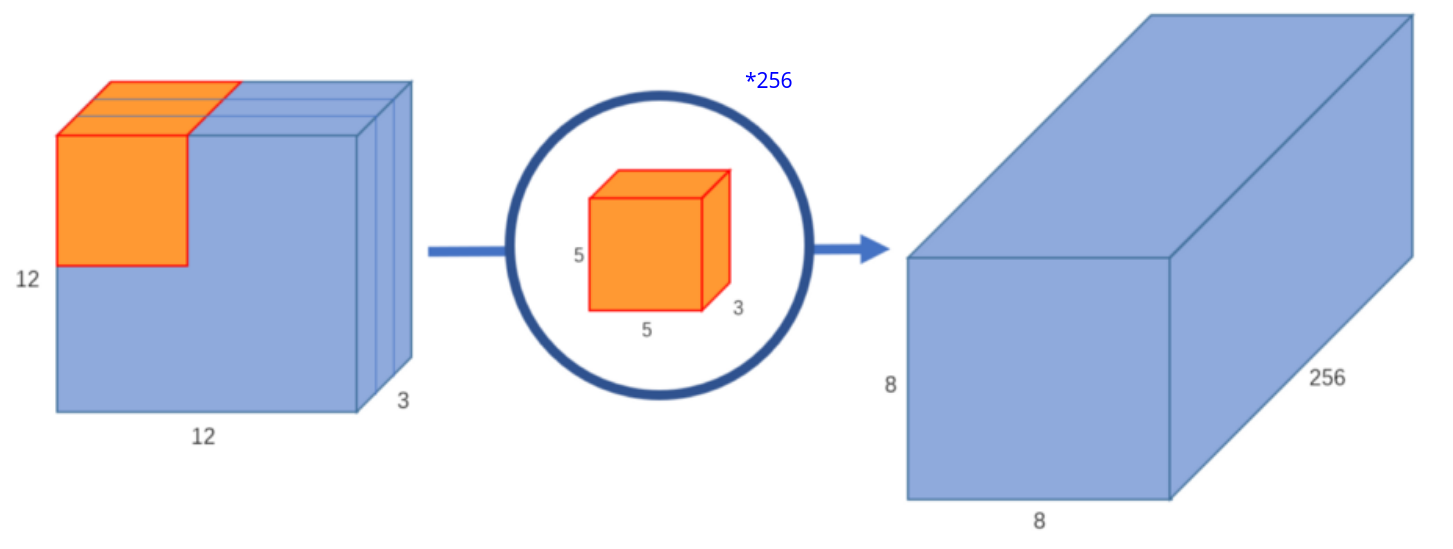
标准卷积 :
对于一个标准卷积核,其通道数与输入特征图通道数相同,我们通过控制卷积核的数量来控制输出的通道数 ,如下图
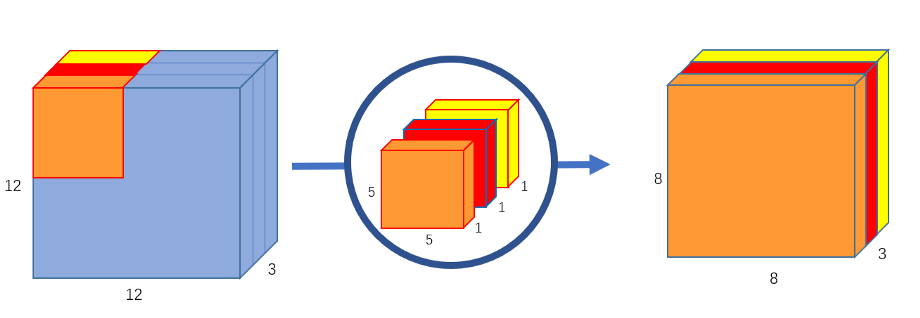
深度可分离卷积 :
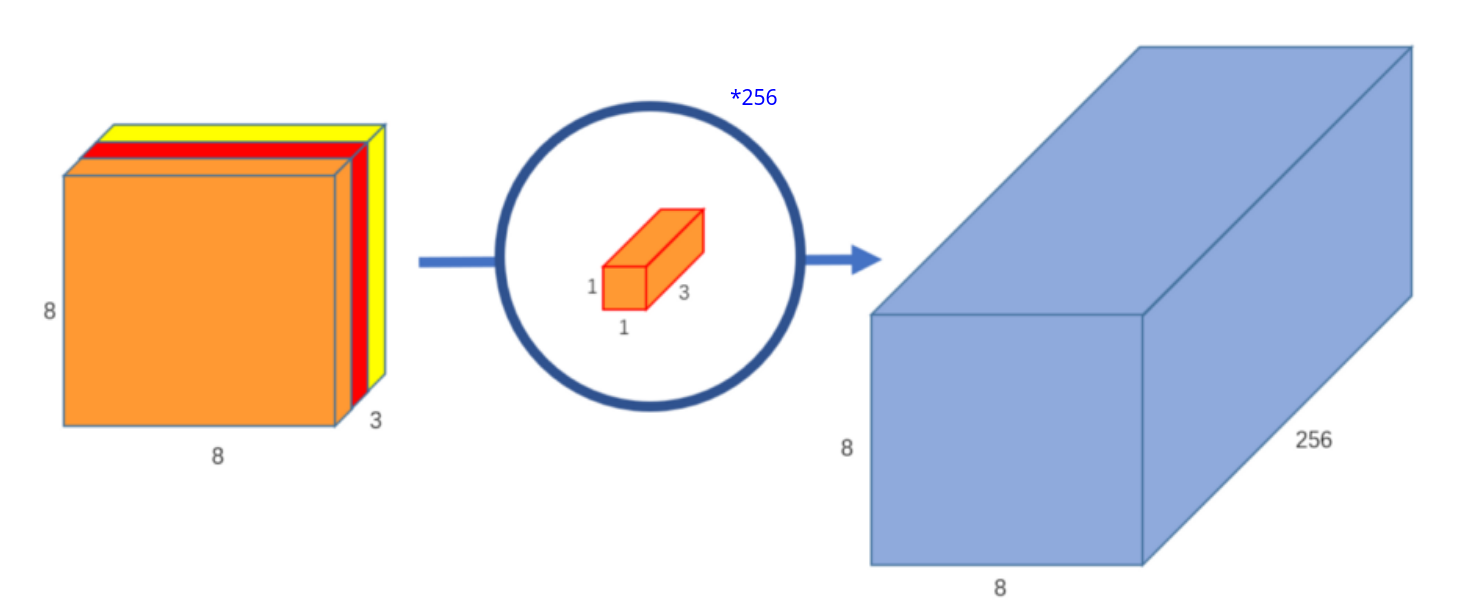
简单来说,深度可分离卷积 = = = + + + P o i n t − w i s e Point-wise P o in t − w i se
深度卷积就是使用与输入特征图通道数相同个数 的单通道卷积核 ,示意图如下:
逐点卷积即是我们经常说的 1 × 1 1\times 1 1 × 1 升维 ,示意图如下:
结合上述三副图可以看到深度可分离卷积与标准卷积的输入大小是相同的,那么深度可分离卷积有什么优点呢 ?
我们知道,当输入和输出的通道数都很大时,标准卷积参数量和计算量都是惊人的:
P a r a m s : k w × k h × C i n × C o u t (1) Params:k_w\times k_h\times C_{in}\times C_{out}\tag1 P a r am s : k w × k h × C in × C o u t ( 1 ) F l o p s : k w × k h × C i n × C o u t × W × H (2) Flops:k_w\times k_h\times C_{in}\times C_{out}\times W\times H\tag2 Fl o p s : k w × k h × C in × C o u t × W × H ( 2 ) 而对于深度可分离卷积:
P a r a m s : k w × k h × C i n + C i n × C o u t (3) Params:k_w\times k_h\times C_{in}+C_{in}\times C_{out}\tag3 P a r am s : k w × k h × C in + C in × C o u t ( 3 ) F l o p s : k w × k h × C i n × W × H + C i n × C o u t × W × H (4) Flops:k_w\times k_h\times C_{in}\times W\times H+C_{in}\times C_{out}\times W\times H\tag4 Fl o p s : k w × k h × C in × W × H + C in × C o u t × W × H ( 4 ) 将 ( 3 ) (3) ( 3 ) ( 1 ) (1) ( 1 ) ( 4 ) (4) ( 4 ) ( 2 ) (2) ( 2 )
k w ⋅ k h + C o u t k w ⋅ k h ⋅ C o u t = 1 C o u t + 1 k w ⋅ k h \frac{k_w\cdot k_h+C_{out}}{k_w\cdot k_h\cdot C_{out}}=\frac{1}{C_{out}}+\frac{1}{k_w\cdot k_h} k w ⋅ k h ⋅ C o u t k w ⋅ k h + C o u t = C o u t 1 + k w ⋅ k h 1 对于我们常用的 3 × 3 3\times3 3 × 3 1 9 \frac{1}{9} 9 1 1 8 \frac18 8 1
网络结构
卷积层
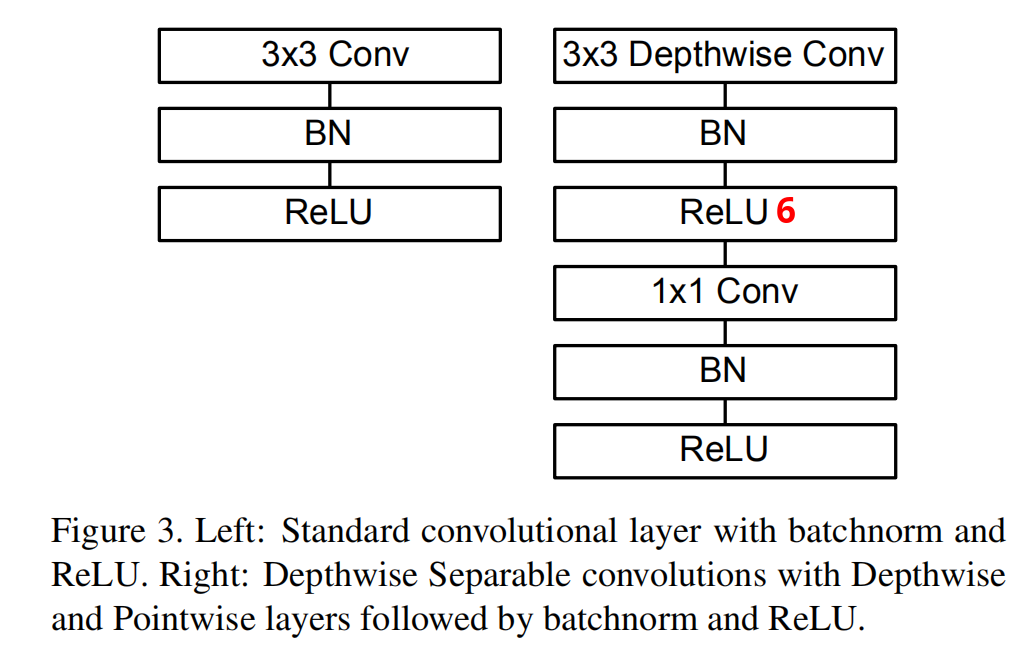
上图左侧是一个常见的 C o n v X : C o n v + B N + R e L U ConvX:Conv+BN+ReLU C o n v X : C o n v + BN + R e LU
需要注意的是,这里使用了 R e L U 6 = m i n ( m a x ( 0 , x ) , 6 ) ReLU6=min(max(0,x),6) R e LU 6 = min ( ma x ( 0 , x ) , 6 ) R e L U ReLU R e LU 在低精度计算下具有更强的鲁棒性
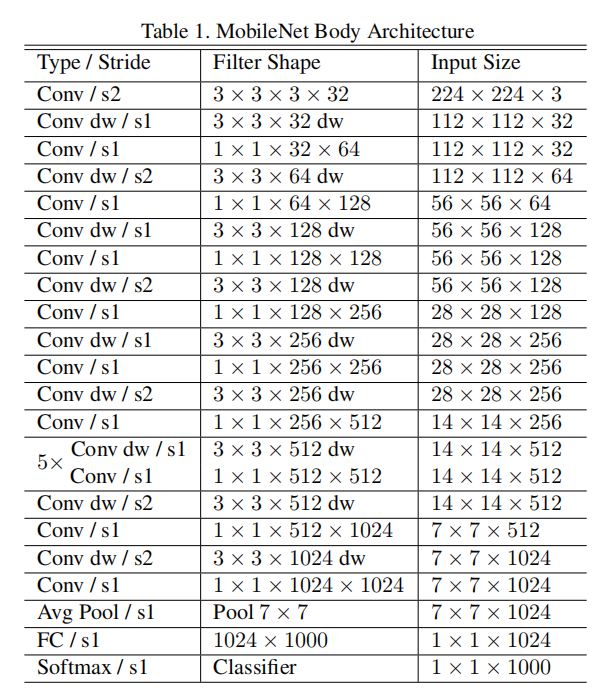
主体结构
仅在第一层使用标准 3 × 3 3\times 3 3 × 3 s o f t m a x softmax so f t ma x
需要注意的是,深度可分离卷积在这里表示成两个层——C o n v d w + C o n v 1 × 1 Conv\ dw+Conv\ 1\times1 C o n v d w + C o n v 1 × 1
更小的模型
尽管最基本的 MobileNet 已经非常小了,但很多时候特定的案例或者应用可能会要求模型更小更快。为了构建这些更小并且计算量更小的模型,引入了一个超参数 α ∈ ( 0 , 1 ] \alpha\in(0,1] α ∈ ( 0 , 1 ]
P a r a m s : k w × k h × α C i n + α C i n × C o u t F l o p s : k w × k h × α C i n × W × H + α C i n × α C o u t × W × H Params:k_w\times k_h\times \alpha C_{in}+\alpha C_{in}\times C_{out}\\
Flops:k_w\times k_h\times \alpha C_{in}\times W\times H+\alpha C_{in}\times \alpha C_{out}\times W\times H P a r am s : k w × k h × α C in + α C in × C o u t Fl o p s : k w × k h × α C in × W × H + α C in × α C o u t × W × H α \alpha α ρ ∈ ( 0 , 1 ] \rho\in (0,1] ρ ∈ ( 0 , 1 ]
P a r a m s : k w × k h × α C i n + α C i n × C o u t F l o p s : k w × k h × α C i n × ρ W × ρ H + α C i n × α C o u t × ρ W × ρ H Params:k_w\times k_h\times \alpha C_{in}+\alpha C_{in}\times C_{out}\\
Flops:k_w\times k_h\times \alpha C_{in}\times \rho W\times \rho H+\alpha C_{in}\times \alpha C_{out}\times \rho W\times \rho H P a r am s : k w × k h × α C in + α C in × C o u t Fl o p s : k w × k h × α C in × ρ W × ρ H + α C in × α C o u t × ρ W × ρ H
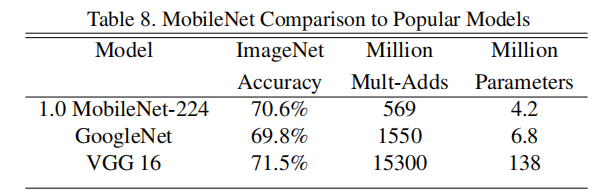
十分优秀
MobileNet V2
时隔一年,谷歌提出 M o b i l e N e t V 2 : I n v e r t e d R e s i d u a l s a n d L i n e a r B o t t l e n e c k s MobileNetV2:Inverted\ Residuals\ and\ Linear\ Bottlenecks M o bi l e N e t V 2 : I n v er t e d R es i d u a l s an d L in e a r B o ttl e n ec k s
从论文名称可以看出 V 2 V2 V 2 V 2 V2 V 2
ReLU、数据坍塌和流形
人们在 M o b i l e N e t V 1 MobileNetV1 M o bi l e N e t V 1 0 0 0
作者认为是 R e L U ReLU R e LU
可以看到输入是一个在二维空间内的螺旋线,通过 N N N T T T N N N R e L U ReLU R e LU T − 1 T^{-1} T − 1
X o u t = R e L U ( T X i n ) T − 1 X_{out}=ReLU(TX_{in})T^{-1} X o u t = R e LU ( T X in ) T − 1 作者在这里表明:如果输入流形可以嵌入到激活空间的一个低维子空间中,那么 ReLU 变换保留了信息,同时将所需的复杂性引入到可表达函数集中 ,其实和上面的总结意思相同,激活空间便是 R e L U ( T X i n ) ReLU(TX_{in}) R e LU ( T X in ) 激活空间的一个低维子空间中 。当嵌入空间维度过低时,会丢失大量信息,也就是数据坍缩,而当嵌入维度较高时,信息则会得到良好的保存
总结 :简单来说 ,这个实验表明,由低维度(通道数)到高维度之后使用 R e L U ReLU R e LU
Insight :
作者通过这个实验提出了两点见解(i n s i g h t insight in s i g h t
If the manifold of interest remains non-zero volume after ReLU transformation, it corresponds to a linear transformation.(如果在 ReLU 之后兴趣流形仍然保持非零体积,则认为它对应线性变换)
ReLU is capable of preserving complete information about the input manifold, but only if the input manifold lies in a low-dimensional subspace of the input space.(ReLU 函数拥有保存输入流形完整信息的能力,但是仅限于输入流形位于输入空间的低维子空间内)
首先,我们需要了解流形 :
流形是几何学和拓扑学中重要的概念,在数据科学中,我们认为数据在其嵌入空间中形成低维��流形,也就是说,我们所观察到的数据是由一个低维流形映射到高维空间上的 ,在高维空间存在一定的冗余,数据可以在更低的维度表示。
关于流形的一个最典型的应用就是分类任务,其目的就是从根本上分离出一堆混乱的流形,这也被称为流形学习 。
那么上述两个见解是什么意思呢?笔者仅根据自己的理解解释:
这里可能是将 R e L U ReLU R e LU L i n e a r B o t t l e n e c k Linear\ Bottleneck L in e a r B o ttl e n ec k
我们已经知道数据实际上是存留在数据空间的低维流形上,当输入的维度(在网络中表现为通道数)很低时,此时,输入流形并不符合处于输入空间的低维子空间内 ,因此会造成大量的信息损失,反过来说,输入流形并不能嵌入到激活空间的一个低维子空间中,R e L U ReLU R e LU L i n e a r B o t t l e n e c k Linear\ Bottleneck L in e a r B o ttl e n ec k R e L U ReLU R e LU
Inverted Residuals with Linear Bottlenecks
为了解决 R e L U ReLU R e LU I n v e r t e d R e s i d u a l s w i t h L i n e a r B o t t l e n e c k s Inverted\ Residuals\ with\ Linear\ Bottlenecks I n v er t e d R es i d u a l s w i t h L in e a r B o ttl e n ec k s L i n e a r B o t t l e n e c k s Linear\ Bottlenecks L in e a r B o ttl e n ec k s