RepLKNet
论文名称:Scaling Up Y our Kernels to 31x31: Revisiting Large Kernel Design in CNNs
作者:Xiaohan Ding, Xiangyu Zhang, Jungong Han, Guiguang Ding
摘要
本文重新审视了现代卷积神经网络中的大核设计,证明了使用一些大核比一堆小核可能更加强大,同时提出了五个设计准则,依据这些准则设计了 RepLKNet——一个纯粹的 CNN 架构,其中卷积核的最大尺寸达到了 。
RepKLNet 在 ImageNet 以及各种下游任务上取得了更好的结果,缩短了 CNN 与 ViT 之间的差距。基于大核的研究进一步表明,与小核相比,大核的 CNN 具有更大的有效感受野和更高的形状偏置(shape bias)
CNN 与 ViT
Transformer 性能强的原因
众所周知,Transformer 是由 self-attention 构成的,相较于 Convolution,self-attention 主要有两点区别:
一是 self-attention 多是在全局尺度内进行计算,即使是最近的 Local Transformer 也是在 的窗口内计算;
二是 self-attention 的核心机制——QKV 运算。
那么其中的关键是哪一点呢?
目前很多相关工作都表明,更大的窗口大小或许才是 Transformer 强大的关键。
Demystifying local vision transformer: Sparse connectivity, weight sharing, and dynamic weight 证明了即使将 Swin 中的 self-attention 换成同样大小的卷积性能不变甚至更好; Mlp-mixer 证明将 ViT 中的 attention 替换为 MLP 性能也很好;Metaformer 将 attention 替换为 pooling 性能还是很好。
CNN 的感受野
自 VGG 以来,不断堆叠小 kernel、加深网络层数成为了卷积神经网络设计的主流范式,因为我们相信,三层 的卷积核的感受野与一层 的感受野相同,并且性能更好,因为其中可以加入更多的非线性,层数越多就代表着拟合能力越强。
这是真的吗
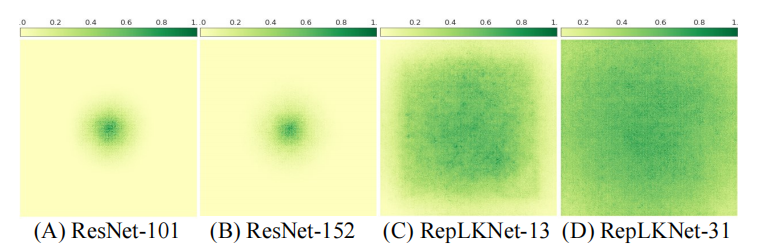
上图为各个网络的输入对于输出中心点的贡献度,可以看到,即使 ResNet 堆叠了 100 多层,其有效感受野也没有多少变化,而 RepLKNet-31 的有效感受野几乎覆盖全图。
该观点在论文 Understanding the effective receptive field in deep convolutional neural networks. NeurIPS 2016.中有所提及,其认为模型的有效感受野正比于 ,即有效感受野的增长与堆叠层数成开方关系。
为什么我们不用大 Kernel
这是一个很显而易见的问题,大 kernel 太大了,我们都清楚卷积核的参数量相对于 kernel size 是呈平方增长的,其速度也会慢很多。
另一个问题就是某些相关工作表明大 kernel 反而会掉点。
虽然历史淘汰了大 Kernel,但是这不表明现在不能复兴它。
虽然标准的 dence 卷积参数量很大并且速度很慢,但是 Depth-with 卷积的参数增长并没有那么大,加上适当的底层优化速度或许也可以很快。
现代神经网络的架构设计或许可以使大 kernel 绽放出新的光彩,比如 swin 的结构。
如何复兴大 Kernel
本文提出了使用使用大 kernel 的五大准则。
Depth-wise+ 底层优化
由于 dence 卷积的参数量与输入输出通道数都有关系,而 Depth-wise 卷积只与输入通道数有关系,一般来说其参数大小是 dence 卷积的几百分之一,即使增大 kernel size,其参数量也只和 dence 卷积相当,论文中也给出了参数表格:
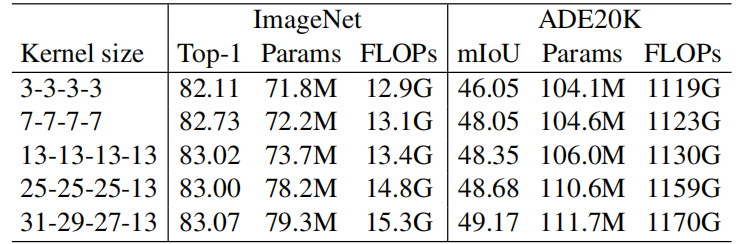
可以看到即使 kernel size 提升了很多,参数量和浮点计算量也没有增加很多。
虽然解决了参数和计算量的问题,但是速度的问题怎么解决呢?
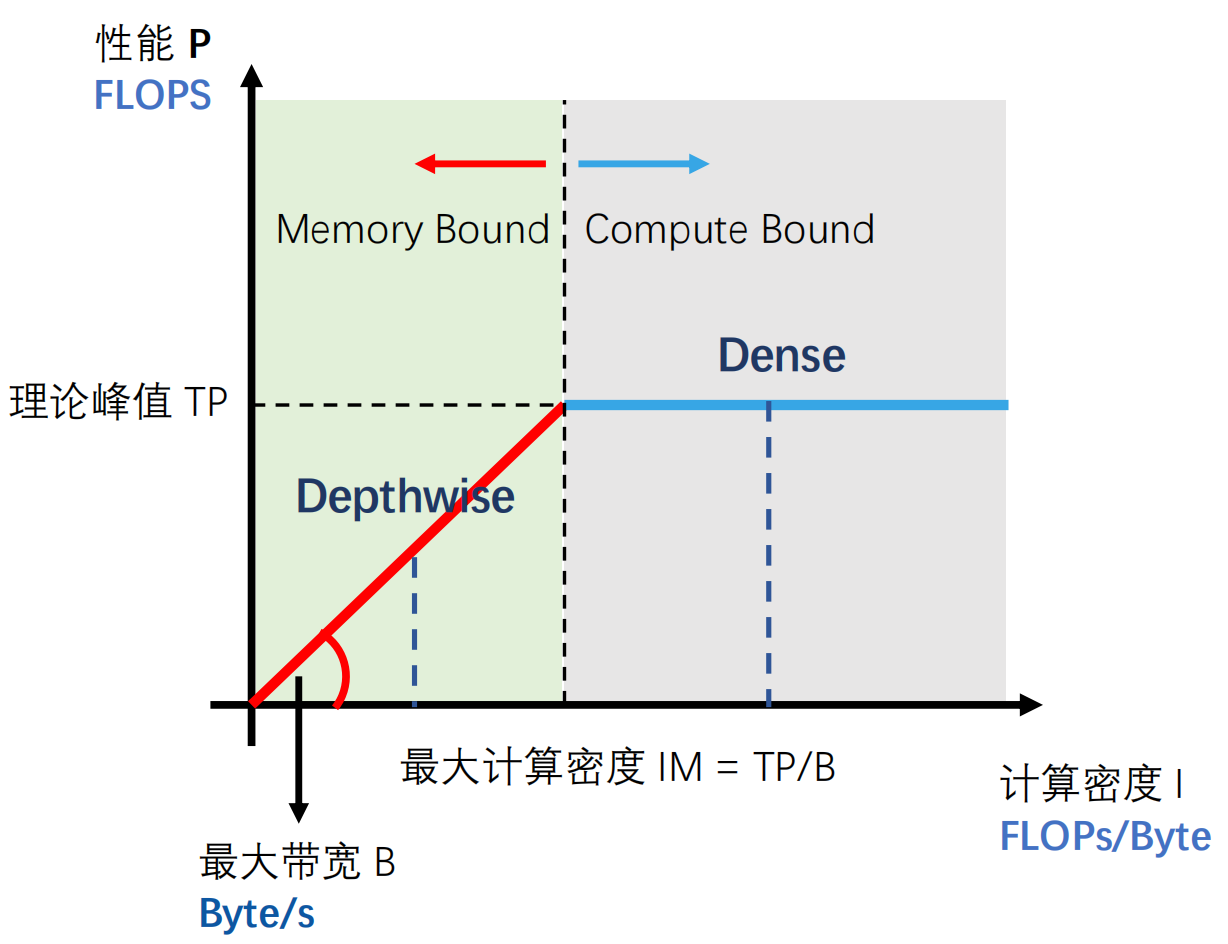
dence 卷积处于上图中的 Compute Bound 区域,��其计算密度已经不会再增长了,除非计算能力上升。
depthwise 卷积处于上图中的 Memory Bound 区域,其计算密度会随着 kernel size 的增长而增长,所以更大的 kernel 速度并不会太慢。
底层优化略过。。。
效果如下:
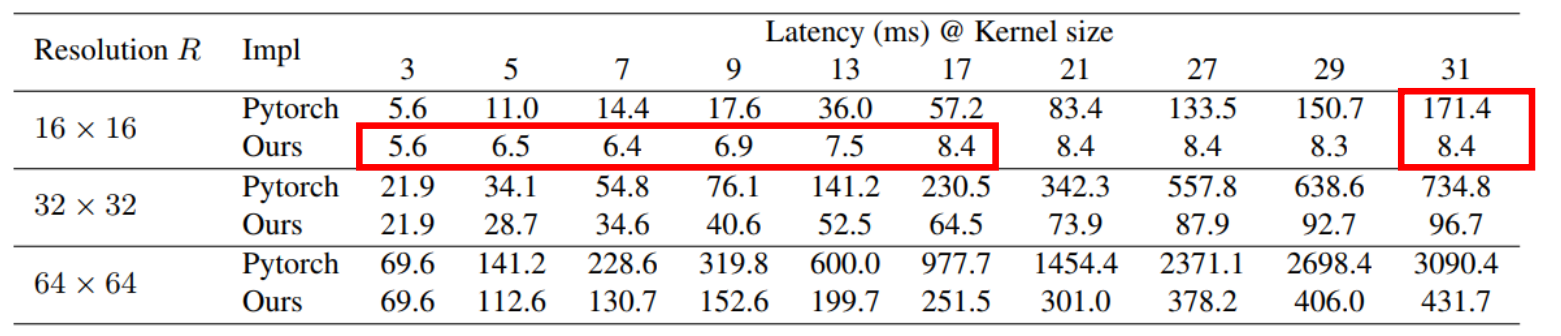
相比于 Pytorch 最高可加速 20 倍。
使用 shortcut
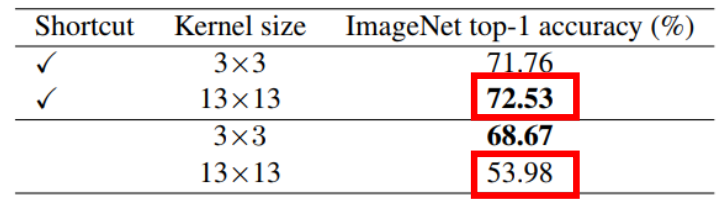
在 MobileNet V2 上的实验,可以看到没有 shortcut 掉点十分严重;这里的解释原因与 RepVGG 中的相同,使用 shortcut 相当于集成了很多隐式的模型,有很多不同大小组合式感受野;没有 shortcut,感受野则单一且巨大,难以捕捉小的特征。
使用小 kernl 做重参数化
继续发扬重参数化,与 RepVGG 类似,同时使用一个并行的小 kernel,推理时重参数化即可。

不论大 kernel 有多大,同时添加一个 的小 kernel,使得组合式的感受野更加丰富,更易提取小的特征。
但是在数据量很大(MegData-73M)时,小 kernel 重参数化效果不大。
看下游任务
的大 kernel 在 ImageNet 分类任务上已经达到极限,即使 size 再增大,性能也不会变化,这点可能是因为 ImageNet 上主要依靠纹理信息。
而对于下游任务,如语义分割、目标检测等,更大的 kernel 还能获得更好的性能。
小 feature map 上使用大 kernel
即使 feature map 尺寸小于 kernel size 也没有关系,底层实现会使用 feature 来卷 kernel,虽然这样会一定程度上失去平移不变性,但是相关工作表明平移不变性不一定就是好的。
RepLKNet
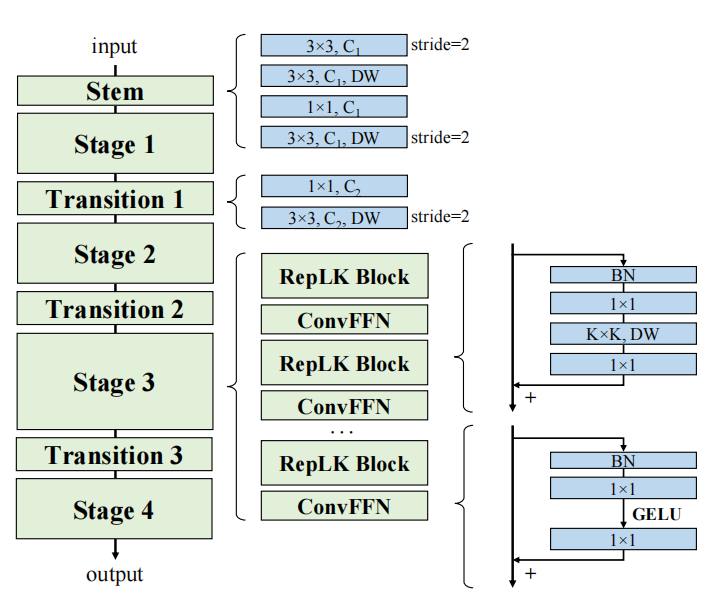
基于上述准则设计了 RepLKNet,并且借鉴了 Swin 的宏观架构,并且继续加大 kernel size,从 7 到 13 到 25,再到最大 31,在各类任务上都取得了十分优秀的效果。
Shape bias
人类用来分辨视觉信息多是因为 shape bias,很多情况下都是根据形状来进行判断的。
而之前的小 kernel 模型由于有效感受野有限,其判断结果使用的为纹理信息,也有很经典的相关工作表明将不同类别的纹理进行替换,网络会错误的给出判断。
经过一些实验发现或许大 kernel 的 shape bias 会更高,而和 attention 的关系不大,这些都是后来的研究目标了。
科研哲学(鸡汤)
最后来喝一碗鸡汤,来看看从小 kernel 到大 kernel 的辛酸发展历程吧。
