论文名称:Deep High-Resolution Representation Learning for Human Pose Estimation
作者:Ke Sun,Bin Xiao,Dong Liu,Jingdong Wang
Code:https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
摘要
- 针对任务:人体姿态估计问题(无关紧要)
- 现有的大多数网络都是将 feature map 由高分辨率下采样到低分辨率,再由低分辨率到高分辨率,相反,HRNET 在整个过程中一直保持着高分辨率表示,以高分辨率子网为第一 stage,逐步增加低分辨率的子网,形成多个 stage,通过反复的多尺度融合来获得更丰富的高分辨率表示:
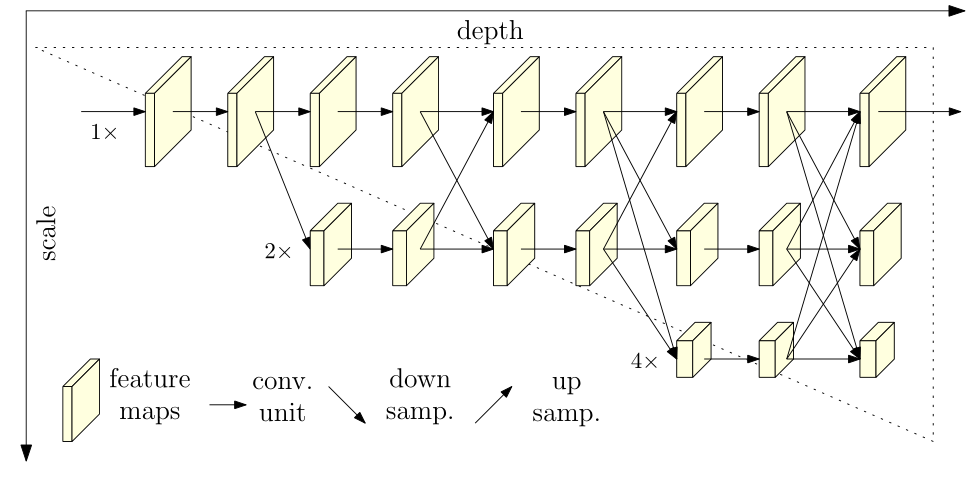
介绍
-
HRNET 以并行的方式连接 Hight to low resolution 子网,可以一直保持高分辨率;同时利用相同深度和尺度近似的低分辨率来表示高分辨率,因此预测的热力图可能更精确。
-
回归关键点位置与关键点热力图估计:大多数用于关键点热图估计的卷积神经网络由一个类似于分类网络的主干网络组成,它降低了分辨率,输出一个与输入相同大小的图,后面紧接着回归预测关键点位置。其主体结构主要采用 hight to low,low to hight,中间辅以多尺度融合和中继监督。
-
中继监督:直接对整个网络进行梯度下降,输出层的误差经过多层反向传播会大幅减小,在每个阶段的输出上都计算损失。这种方法可以保证底层参数正��常更新。
-
相关网络:
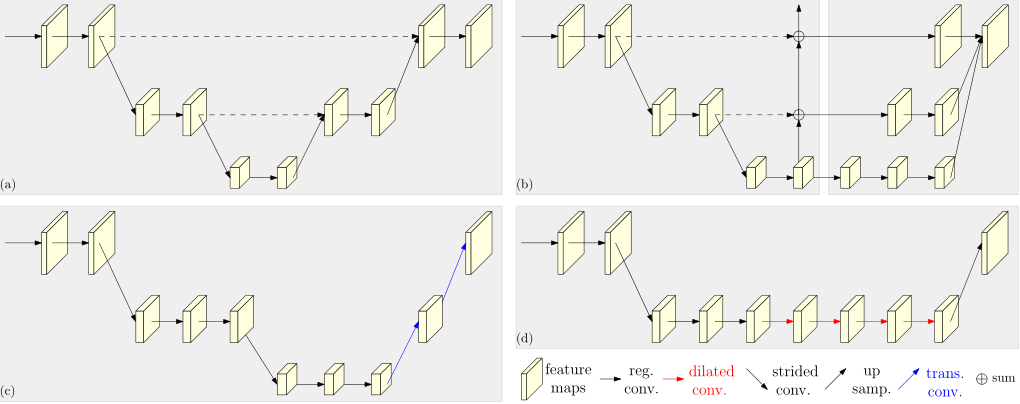
a 图为 Hourglass,b 图为 Cascade pyramid,c 图为 SimpleBaseline,d 图使用了空洞卷积。
具体方法及实现细节
重复的多尺度特征融合:
在并行自网络中加入交换单元:
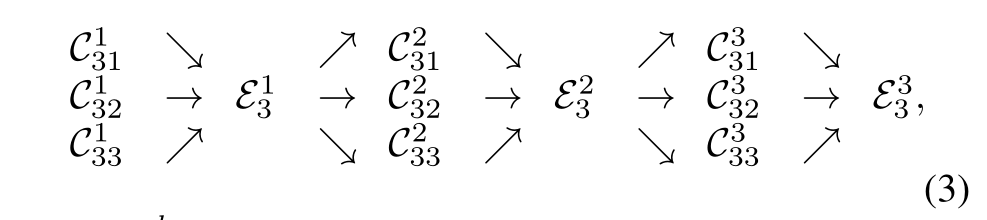
以 stage3 为例:
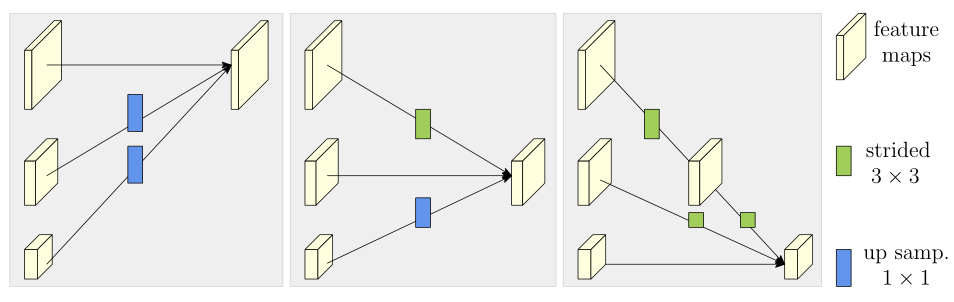
其实十分简单,分为三种情况:
- hight to low 使用步长为 2 的 3X3 卷积
- low to hight 使用最近邻插值加 1X1 卷积统一通道数
- 同层直接复制。
损失函数与 groundtruth
- 损失函数使用均方差函数
- grountruth 采用二维高斯分布,以每个关键点的 grouptruth 位置为中心,标准差为 1 像素生成。
网络结构
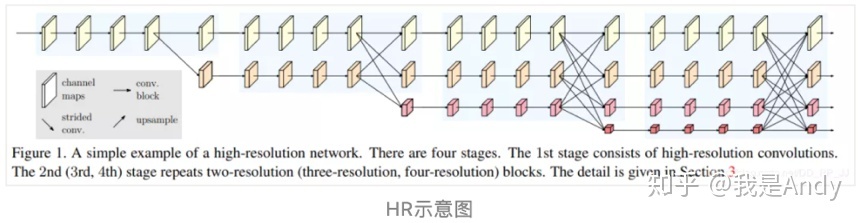
- 包含四个 stage 和四个并行子网络,其分辨率逐渐减少一半,相应的通道数增加两倍。
- 第一个 stage 包含四个残差单元,每个单元有一个宽度为 64 的 bottleneck,后面紧跟一个 3X3 的卷积核减少通道数。
- 后三个 stage 分别包含 1、4、3 个交换单元。
- 作者分别研究了一个小网络和一个大网络,HRNET-W32 和 HRNET-W48,其后三个 stage 的宽度分别为:【64,128,256】、【96,192,384】。
分支输出的选取
对于四个分支的最终输出的选取,可以自己实验,主要有四种:
-
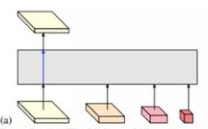
只选择最高分辨率的输出
-
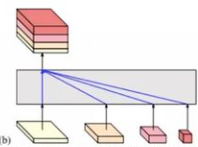
将其余三个上采样至原图大小 caoncat,主要用于语义分割和面部关键点检测
-
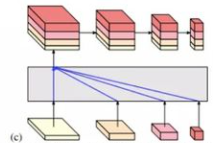
在第二步基础上对所有的输出使用了一个特征金字塔,主要用于目标检测
-
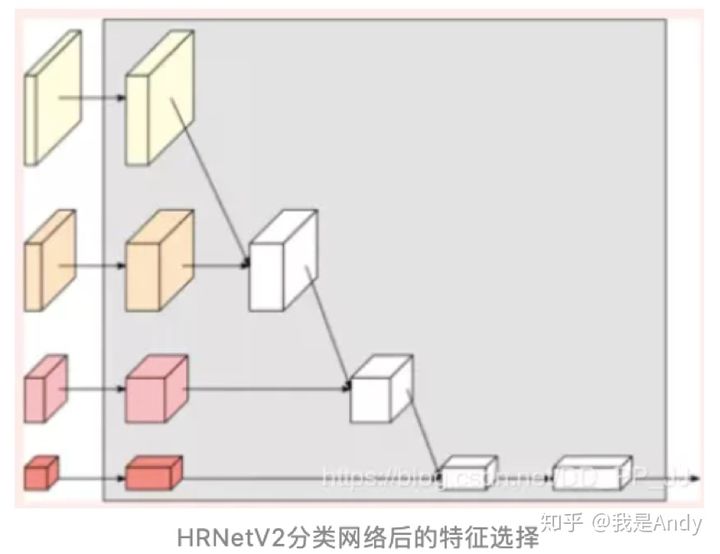
主要用于分类网络
总结
优点
- HRNet 并行地连接 high-to-low 分辨率子网络,在整个网络中保持高分辨率,并且预测得到的热图空间上可能更精确;
- 疯狂的多尺度特征融合使得网络性能有所提升;
- 不需要进行中继监督。
缺点
- 计算量大,需要设备支持。
探索
- 可以探索更多的信息交换方式
- 可以增加网络的深度