FCN-PanopticSeg
论文名称:Fully Convolutional Networks for Panoptic Segmentation
作者:Yanwei Li,Hengshuang Zhao,Xiaojuan Qi,Liwei Wang,Zeming Li,Jian Sun,Jiaya Jia
摘要
-
提出一个简单、强大、高效的全景分割框架——全景 FCN,旨在使用一个统一的全卷积网络表示和预测背景和前景实例;
-
提出内核生成器(kernel generator),将每个对象实例或背景类别编码为特定的内核权重,并且通过对高分辨率特征图进行卷积直接生成预测;通过这种方法可以同时满足前景实例和背景之间相冲突的属性:
- 在全景分割中,可数和不可数的实例被分为 thing 和 stuff,代表着前景实例和背景。为了区分各种 id,thing 通常依赖于实例感知(instance-aware)特征,这些特征是随对象而异;
- 而对于 staff,其更偏好于语义一致性(semantically consistent),这保证具有相同语义信息的像素预测相同。
个体因内在差异而不同,而背景却因内在一致而相似,以往的工作很难同时提取这两种信息。
-
相较于之前工作拥有更高的效率和性能。
Panoptic FCN
Panoptic FCN 在概念上十分简单:
- 引入核生成器(kernel generator) 为不同类别的 thing 和 stuff 生成核权重;
- 核融合(kernel fusion)将不同 stage 具有相同 identity 的核权重融合起来;
- 使用特征编码器(feature encoder)编码高分辨率特征。
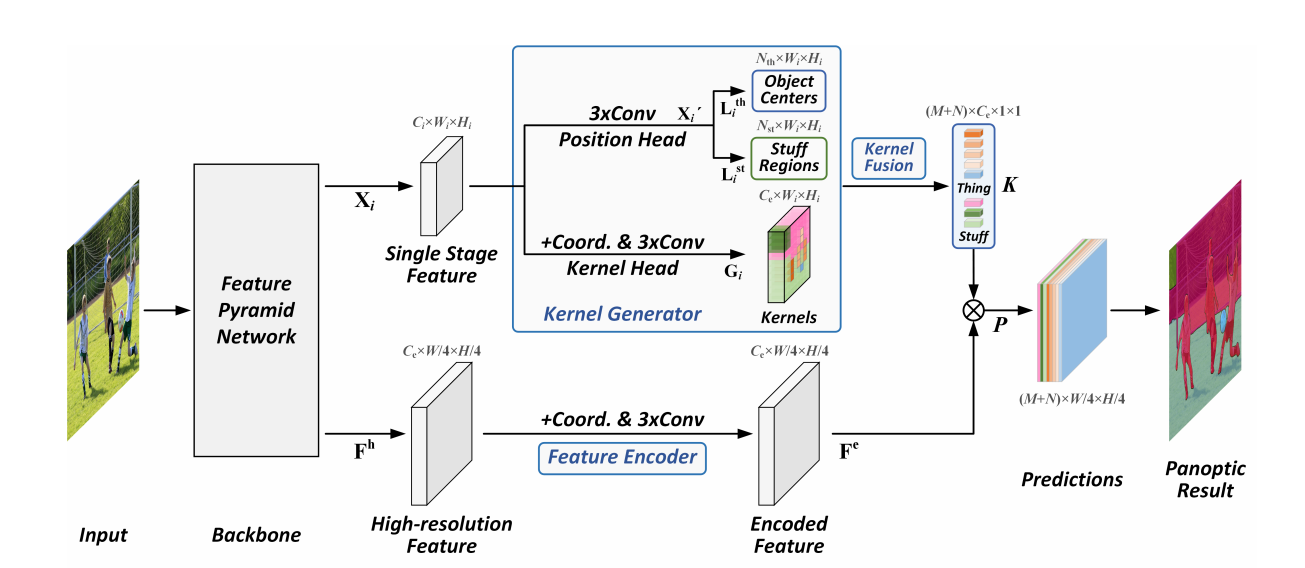
kernel generator
给定 表示 FPN 第 个 stage 的输出, 表示核权重, 分别表示 thing 和 stuff 的位置。
Position Head 用于实例定位和分类;kernel Head 用于生成权重。
Position Head
对于输入 ,简单的堆叠卷积层对特征图进行编码得到 ,之后需要对其中每个实例进行定位和分类。
不同于以往的工作,这里将具有**相同语义信息的背景也视作一个实例,**其对应的映射 和 可由卷积直接生成, 分别表示其语义类别数。
为了更好的优化其生成,使用不同的策略来生成 GT:
-
对于 C 类中的第 K 个对象,使用高斯核将正关键点拆分到 Heatmap 的第 c 个通道
其中, 是第 k 个对象的中心 是对象尺寸的标准误差
有 解释 说这是为了消除下采样和上采样过程中产生的偏差
大概是说将不同类别实例分到不同的通道上,并且不同的正关键点代表不同的实例
-
对于 stuff,将 GT 编码为 One-hot 向量,并使用双线性插值到对应尺寸(?)。
使用 Focal Loss 来指导 Position Head 的优化,具体定义如下:
总的 loss 为:
在推理过程中,图中值为 1 的点 和 被认为是对象中心或是背景区域,将在后面详细解释。
Kernel Head
在这里使用�了 CoordConv 用于获取更多的位置信息,其具体做法是将横纵坐标归一化,分别生成一张图,最后 Concat 在输入特征图后
使用堆叠的卷积层来生成权重 ,给定 Position Head 中的 ,认为 中对应的坐标位置的向量 表示对应的实例,并且这些向量选取出来用于核融合。
Kernel Fusion
通过内核融合来合并来自 FPN 各个 stage 的 kernel weight,从而分别保证 thing 和 stuff 的实例感知和语义一致性(?),因此不需要使用 NMS 去除重复的实例,融合的 内核 ,AvgCluster 表示平均聚类,候选集合 ,表示拥有和 相同 ID 的内核。
对于 boject centers,如果它们之间的余弦相似度超过给定阈值,则认为其相同;对于 stuff regions,将所有是同一类别的内核都标记为相同的 ID。
利用上述方法,每个 中的 被视为单个对象的嵌入, 是对象总数,这样,具有相同 identity 的内核被合并为 thing 的单个嵌入,并且 中的每一个内核都表示一个单独的对象,这满足了 instance-awareness 的要求。
同样,每个 中的 被视为所有第 j 类像素的嵌入,N 是存在的 stuff 数。这样就将具有相同语义的类别融合为单个嵌入,满足了 semantic-consistency 的要求。
这样一来,Kernel Fusion 便能同时满足这两个条件。
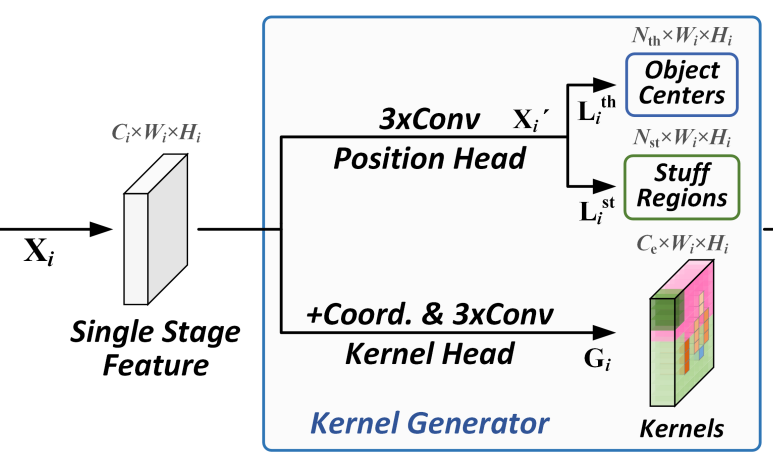
Feature Encoder
为了保留更多实例的细节,使用高分辨率的特征图进行编码,同样使用了 CoordConv 和堆叠的卷积层,最后将得到的 Encoded Feature 与 Kernel Fusion 得到的 kernel 进行卷积操作,得到最终的预测结果。
Training and Inference
Training scheme.
训练阶段,使用每个对象的中心点和 stuff regions 中的所有点生成它们的 kernel;
使用 Dice Loss 对分割预测进行优化;
为了进一步释放 kernel generator 的潜力,对每个对象中的多个正数进行采样,比如在 中 top k 的点,得到一个 的 kernel,于是使用一个加权的 Dice Loss,对同一对象中的不同的点进行加权;对于 stuff 来说将 k 设置为 1,仅仅取值为 1 的点,损失函数定义为:
权值定义为 ,于是总的损失函数为 。
Inference scheme
对于 object center,使用 MaxPool 保留峰值点,相应类别的中心会被保留在相应的通道内,stuff region 也是同理。
推理时会保留 object 前 100 个得分的内核,和所有 stuff 的内核,用于实例生成。
使用 0.4 作为阈值将预测的软掩码二值化。
消融实验
Kernel generator:

使用 3 层可变形卷积扩展了感受野,达到了最好性能,尤其是对 stuff regions,有 1.4%PQ 的提升。
Position embedding:

在 kernel head 和 feature encoder 同时使用 CoordConv,1.4%PQ 的提升。
Kernel fusion:

在阈值设置为 0.9 时达到了最佳效果。

可以看到�,kernel fusion 使得性能饱和,额外的 NMS 并不会带来更多增益。
Feature encoder :

探究不同的通道数对 feature encoder 的影响,64 的通道数可以达到较高的性能,128 的通道数仅仅带来微小的提升。
Weighted dice loss:

当 k 为 7 时带来了 1.1%PQ 的提升。
Upper-bound analysis:

分析该方法在 Res50-FPN 和 COCO 验证集上的上限,直接给出 GT 的位置和类别,可以看到提升及其巨大。
Speed-accuracy:
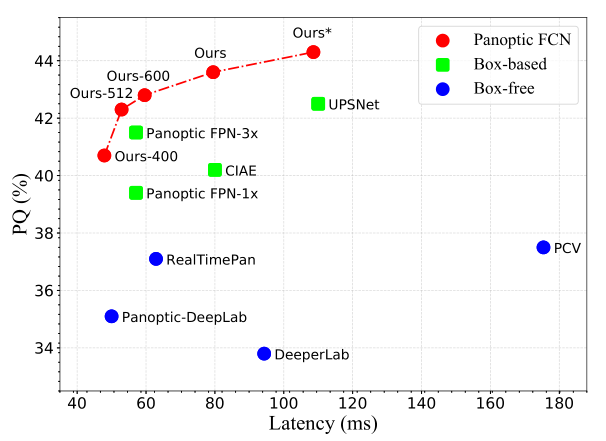
总结
提出了一种简单有效的全景分割 FCN 框架,使用全卷积的方式表示和预测 thing 和 stuff;为此提出了 kernel generator 和 kernel fusion,为每个实例或是背景语义类别生成唯一的 kernel,并且同时满足了 instance-awareness 和 semantic-consistemcy,用 feature encoder 生成的高分辨率特征,直接通过卷积实现预测。