RegSeg
论文名称:Rethink Dilated Convolution for Real-time Semantic Segmentation
作者:Roland Gao
摘要
近来的各种语义分割网络一般都是在 ImageNet 预训练的骨干后加上一个特殊的上下文模块,以快速扩大感受野。虽然其结果十分成功,但是仔细分析就会发现,绝大部分计算量都集中在骨干网络之中,而大部分骨干网络并不能获得足够大的感受野。最近的一些工作通过快速降低骨干网络中的分辨率来解决这一点,并且同时使用一个或者多个具有高分辨的平行分支,比如 BiSeNet、STDC 和 DDRNet 等。
本文使用了不同的方法,设计一个受 ResNeXt 启发的结构,使用两个平行的 3×3 卷积层,每个卷积拥有不同的 dilation rate,扩大感受野的同时也能保留局部的细节特征。
同时提出了一个轻量级的解码器,它比普通的替代方案能恢复更多的局部信息。
RegSeg 的性能十分优秀,并且不需要在 ImageNet 上预训练,作者认为
ResNeXt
在上篇文章中回顾了卷积神经网络的发展史,ResNeXt 也在其中留下了浓墨重彩的一笔。ResNeXt 将 ResNet 与 Inception 结合,可以获得更好的性能。其网络结构图如下:
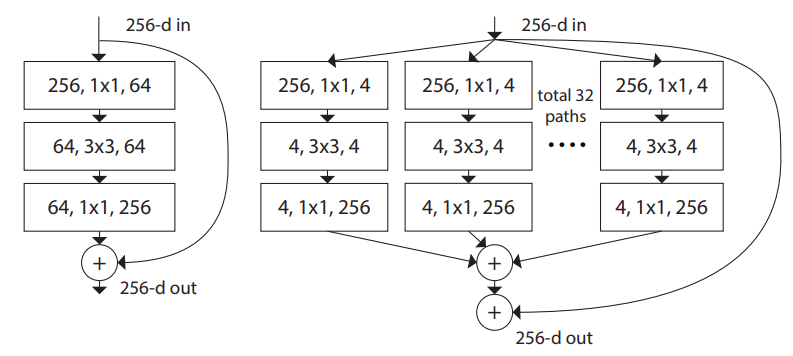
在每个 block 中使用分组卷积,参数量不变的同时获得了不俗的性能,有力地证明了分组卷积的可行性。
RegSeg
backbone
RegSeg 受到 ResNeXt 的启发,同样使用了分组卷积,同时对于每个卷积使用不同的 dilation rate,最大可以达到 14,这是非常令人震惊的设计,但是结果表明,大感受野与小感受野的结合拥有很强的潜力。
RegSeg 的设计如下:
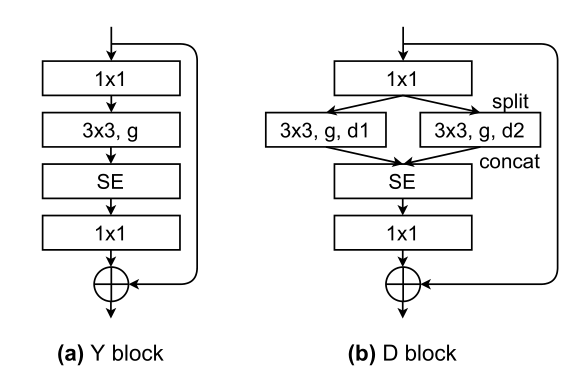
每层中使用两个分支,将特征图 split 后使用不同的分组卷积核来降低参数量,其中一个卷积核的 dilation rate 始终为 1,另一个则拥有很大的空洞率,与此同时使用残差结构来保证性能。
对于 stride=2 的下采样层,其结构如下:
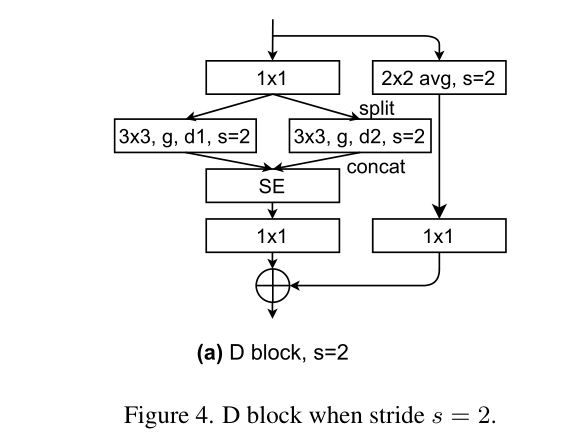
在 identity 的部分添加了步长为 2 的 2×2 卷积。
decoder
设计了一个轻量高效的解码器,结构图如下:
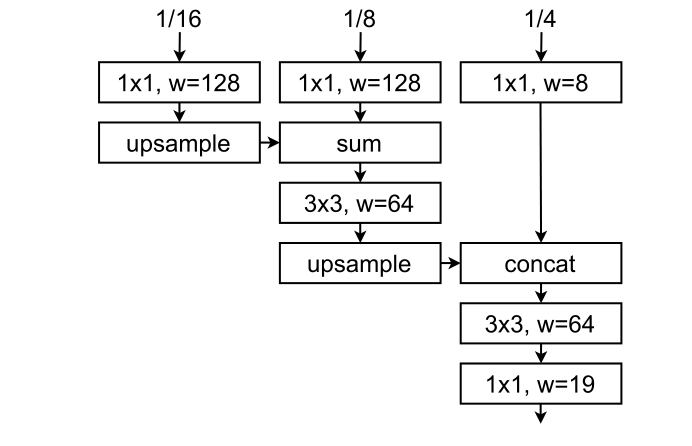
解码器有着恢复主干局部信息的作用,该解码器直接同时对三个尺度的信息的进行恢复,充分利用不同尺度的信息。
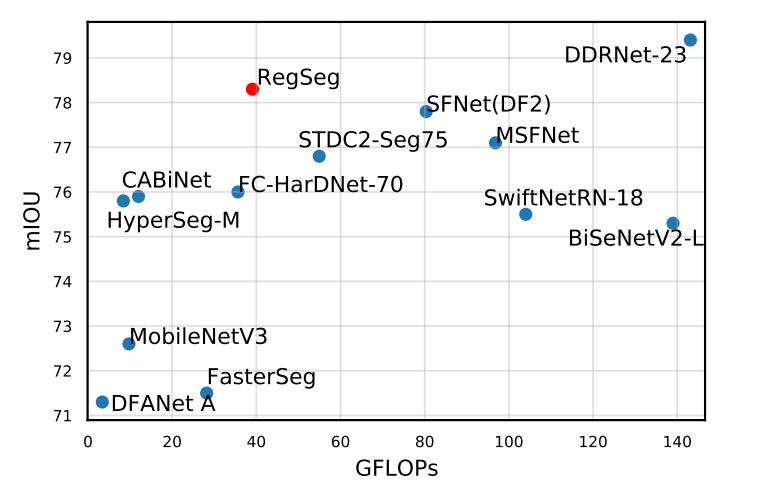
实验
使用不同的配置进行了实验,结果如下:

性能与感受野整体上成正相关,在网络浅层的空洞率比较小,中期之后则使用极大的空洞率。
更多相关细节可以参考论文或者官方实现仓库。
神经网络架构设计
笔者最开始看见这篇论文的多分支结构时便,立刻联想到了 RepVGG 和 Inception,在主干网络中使用不同的分支来获取不同的感受野。一种理论是这相当于有 的个模型隐式地集成在其中,使得模型获得了一种组合式的感受野,从而能对各种尺度的信息都有很好的捕获能力。
然而本文的不同在于,为了保证模型的轻量和效率,没有使用更大尺寸的卷积核来扩大感受野,而是使用了有些违反常识的极大空洞率。同时,也使用了分组卷积来对进一��步轻量化,而上述两篇文章都是对于完整的通道做卷积操作。
不久 RepLKNet 发布,其与 RegSeg 也是有异曲同工之妙,不过 RepLKNet 将 RegSeg 做到了极致,使用深度可分离卷积,以及最大感受野大于 RegSeg 的 31×31 卷积核。RepLKNet 的实验证明,仅仅极大和极小两个感受野的分支即可达到优秀的效果,而更多的分支则不会带来性能提升。
他们之间的不同之处在于,为了减少参数量和提升速度,RegSeg 将通道 split,并且使用了分组卷积而没有 1×1 卷积来混合通道信息,我相信这会导致一定的性能损失。
同时,RepLKNet 依据 Swin Transformer 的宏观架构设计而成,或许有另一种强大的架构等待人们发现。